Message passing
- Synchronous and asynchronous programming model
- Asynchronous communication
- Synchronous request management
- Asynchronous management of requests
- Examples
- Programming and reactive systems
Message passing can be implemented:
- Within a process, via threads. Using buffers or queues, for example.
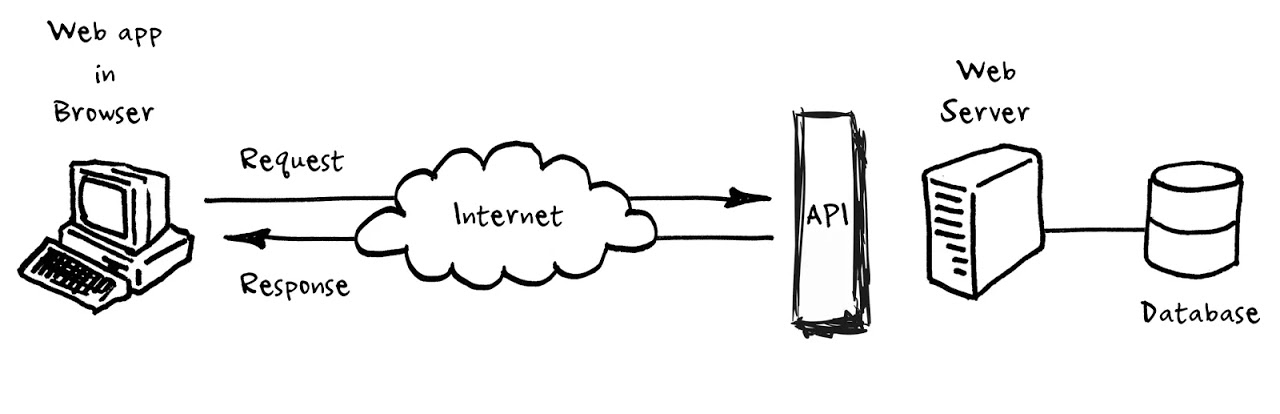
- Between processes. It is usually done using the client/server paradigm and through networks. A possible mechanism is the use of sockets, as can be seen in the UF Sockets and Services. In this communication there is no sharing of mutable data, but it can happen that multiple clients access the same server simultaneously.
A between processes implementation can be seen in the diagram.
Synchronous and asynchronous programming model
Communication between the two parties can be synchronous or asynchronous, depending on whether there is an I/O (input/output) block.
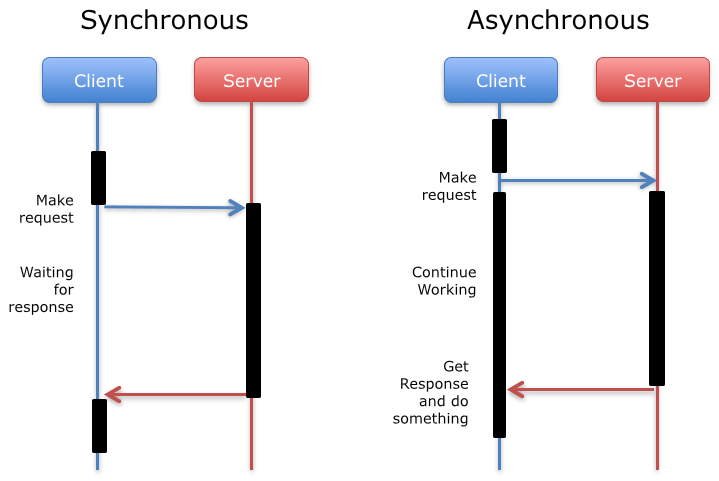
As you can see in the diagram, in the synchronous form the client waits for the response from the server (I/O blocking), and meanwhile does nothing. In the asynchronous form it sends the request, continues working, and at some point receives the response (no I/O blocking).
Which form is more convenient? It depends on the circumstances. The synchronous form is easier to implement, but the asynchronous allows to improve system performance by introducing concurrency.
Asynchronous communication
Asynchronous requests must allow the client to know the result afterwards. Some possible solutions:
- None: The client can only know the result by querying one or several times after (polling).
- A code call: When the request finishes, the server makes a code call. It could be implemented using callbacks.
- A message: When the request finishes, the server sends a message that can be received by the client. This message can travel in different protocols, and is usually implemented using some kind of middleware. Messages typically end up in queues, which are then managed by servers.
Synchronous request management
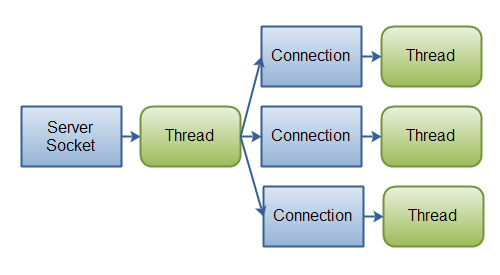
When we use the synchronous model (with blocking), a single thread cannot handle multiple simultaneous requests. This means we need to create a thread to handle each request and return the response. We call it thread-based architecture.
Usually, the number of threads that are allowed to be managed simultaneously is limited to avoid excessive consumption of resources.
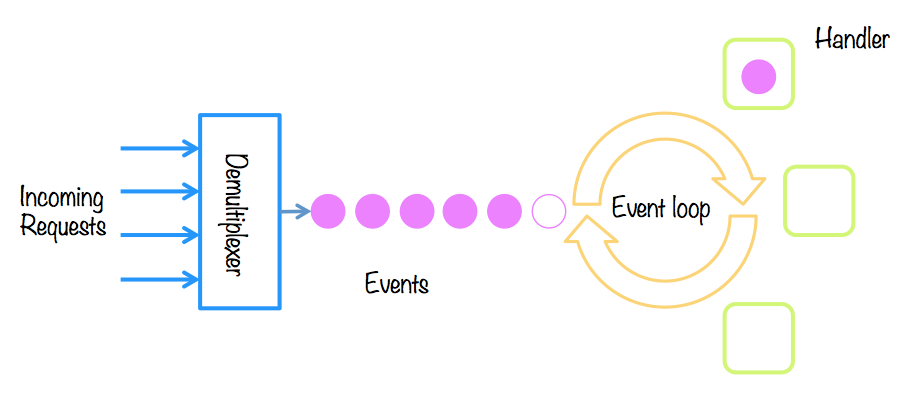
Asynchronous management of requests
The producer-consumer pattern is reproduced: the producers are the origin of the events, and only know that one has occurred; while the consumers need to know that there is a new event, and they must attend to it (handle). We call it event-based architecture.
Some techniques to implement the service:
- The reactor pattern: requests are received and processed synchronously, in the same thread. It works if requests are processed quickly.
- The proactor pattern: requests are received and processing is split asynchronously, introducing concurrency.
In Java we have Vert.x, a multi-reactor implementation (with N event loops).
Another technique for handling asynchronous requests is the actor model. This model allows concurrent programs to be created using non-concurrent actors.
- An actor is a lightweight, decoupled unit of computation.
- Actors have state, but cannot access the state of other actors.
- Can communicate with other actors using immutable asynchronous messages.
- The actor processes messages sequentially, avoiding contention on state.
- Messages may be distributed over the network.
- No specific order is assumed in the messages.
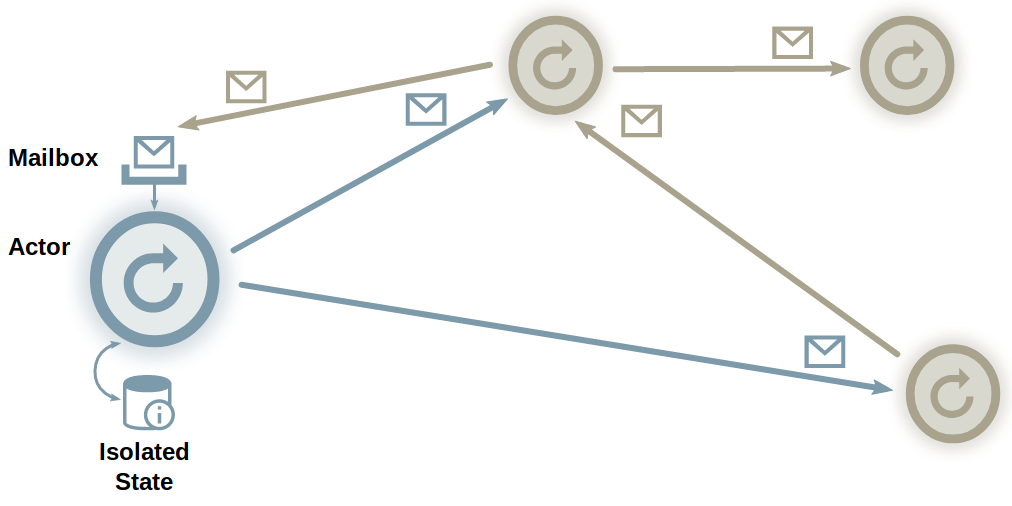
In Java, we have an example library: Akka.
Examples
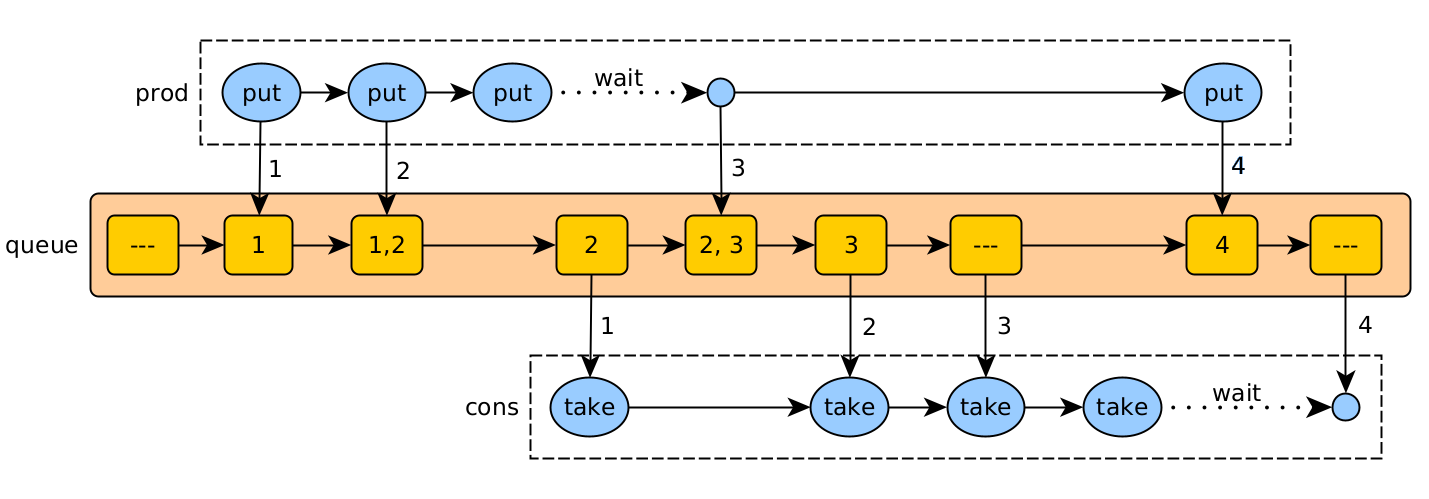
One way to implement it is to pass messages between threads by using a synchronized queue. There may be one or more producers and one or more consumers. The queue must be thread-safe. In Java, the BlockingQueue implementations, ArrayBlockingQueue and LinkedBlockingQueue, are examples. Objects in these queues must be of an immutable type.
Asynchronous buffer (queue)
In this example, a producer thread sends jobs (1, 2, 3, 4) to a consumer thread using a thread-safe queue. The maximum queue size is 2.
The actions are:
- put (prod): add a job, waiting if there is not enough space.
- take (cons): read a job for processing, and wait if there is none.
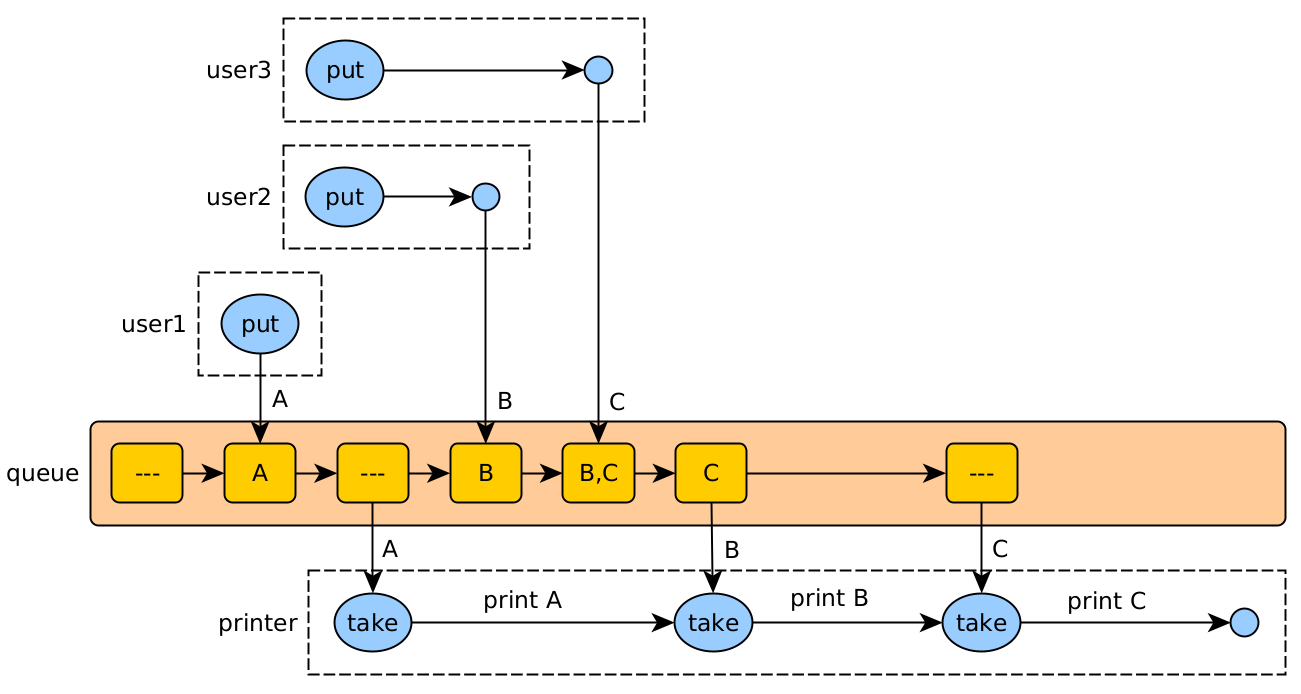
Asynchronous printer call flow
Sometimes requests refer to a shared resource that is not allowed to be used by more than one client at a time. In these cases, you can implement a queue that handles requests asynchronously:
- The client makes the asynchronous request, and later can receive the response or confirmation of the request.
- The server registers the request in a queue, which is served in order by a separate thread.
The printer is a single thread (server) that reads the jobs added to the queue by different users (threads), and attends to them.
We could also have more than one queue, if there is the possibility of having more than one point to serve the requests (several printers).
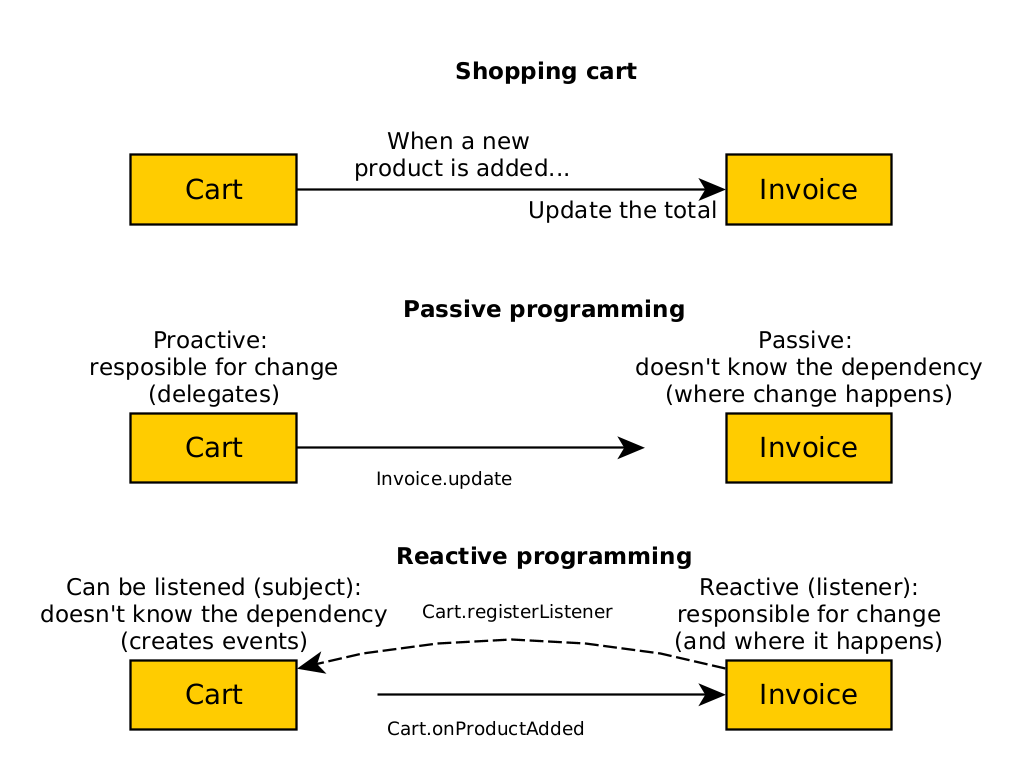
Programming and reactive systems
passive programming is traditional in OO designs: one module delegates to another to produce a change to the model.
The proposed alternative is called reactive programming, where we use callbacks to invert responsibility.
The term "reactive" is used in two contexts:
- reactive programming is based on events (event-driven). An event allows the registration of several observers. It usually works locally.
- reactive systems are generally based on messages (message-driven) with a single destination. They most often correspond to distributed processes that communicate over a network, perhaps as cooperating microservices.
In the shopping cart example, we can see how to implement this with passive and reactive programming:
- With passive, the basket updates the invoice. Therefore, the basket is responsible for the change and depends on the invoice.
- With reactive, the invoice receives a product added event and updates itself. The invoice depends on the basket, as it has to tell it that it wants to hear its events.
Pros and cons:
- Reactive programming allows you to better understand how a module works: you only need to look at its code, since it is responsible for itself. With the passive it is more difficult, since you have to look at the other modules that modify it.
- On the other hand, with passive programming it is easier to understand which modules are affected: by looking at which references are made. With reactive programming you need to look at which modules generate a certain event.
reactive programming is asynchronous and non-blocking. Threads looking for shared resources do not block waiting for the resource to become available. Instead, they continue their execution and are notified later when the service is complete.
Reactive extensions allow imperative languages, such as Java, to implement reactive programming. They do this using asynchronous programming and observable streams, which emit three types of events to their subscribers: next, error, and completed.
Since Java 9 reactive streams have been defined using the Publish-Subscribe (very similar to the observer pattern) using the Flow. The most widely used implementations are Project Reactor (e.g. Spring WebFlux) and RxJava (e.g. Android).
On the other hand, a reactive system is a style of architecture that allows several applications to behave as one, reacting to their environment, keeping track of each other, and allowing their elasticity, resilience and responsiveness, usually based on queues of messages directed to specific receivers (see the Reactive Manifesto). An application of reactive systems are microservices.
Both the reactor/proactor patterns and the actor model allow implementing reactive systems.