Services and processes
Processes and Threads
Learning results:
- Develop multi-process applications recognizing and applying parallel programming principles.
- Develop applications composed of several threads of execution by analyzing and applying specific libraries of the programming language.
References
- Java Concurrency Terminology
- Java Language Specification, capítol 17: Threads and Locks
- The Java tutorials: Concurrency
- Java Concurrency and Multithreading Tutorial
- Threads (Java in a nutshell)
- How to work with wait(), notify() and notifyAll() in Java?
- Thread Communication using wait/notify
- The evolution of the producer / consumer problem in Java
- Java CompletableFuture Tutorial with Examples
- Concurrency in JavaFX 8
- Liveness (The Java Tutorials, Oracle)
- Liveness (Wikipedia)
- The Deadlock Empire
- Thread Safety (6.005: Software Construction)
- What is Thread Dump and How to Analyze them?
Reactive systems programming:
- Reactive Programming: Why It Matters
- Reactive programming vs Reactive systems
- RxJava Wiki
- RxJava Backpressure
- Reactive Manifesto (Glossary)
- RxJava and Reactive Programming
- Understanding RxJava Basics
- The Complete RxJava Roadmap: From Novice to Advanced
- Poor Man's Actors in Java
- Designing Reactive Systems (llibre de Hugh McKee)
- Reactive in practice: A complete guide to event-driven systems development in Java
- A reactive Java landscape
- Reactive Programming with Reactor 3
Concurrency
Concurrency and parallelism
Concurrent computing allows multiple tasks within an application to run in no particular order, out of sequence. In other words: one task does not need to be completed for the next one to begin. This is a property of the algorithm. In other words, we need to design our application to allow it.
Concurrent computing does not imply that execution occurs at the same instant of time. Parallel computing does refer to execution at the same instant of time, and takes advantage of systems with multiple cores to speed up computation. It is a property of the machine.
On the one hand, there are situations where applications are inherently concurrent. On the other hand, if we do not design concurrently, our applications cannot take advantage of the multi-core hardware architectures of computer CPUs, and we will be limited to the capacity and performance of a single core.
Processes and threads
The planner or scheduler of a system is the mechanism that allows assigning tasks to workers. In an application, a task is usually translated into a thread and a worker into a CPU core. The assignment causes the scheduler to replace one task with another. This is called context switching. It is heavy for processes, with a larger context, and light for threads, with a smaller context.
The basic unit of execution of an operating system is the process, which are collections of code, memory, data, and other resources. A process has an independent execution environment, simulating a computer. For example, it has its own independent memory space. They are usually synonymous with program, or application, although it can be a set of processes.

A thread is a sequence of code that runs within the scope of the process, and can share data with other threads. A thread is the minimum sequence of instructions that a scheduler manages. A process can have multiple threads running concurrently within it.
When we develop an application, its data is in two different memory spaces: the heap and the call stack:
-
Call stack: data structure that stores the active routines of a thread stacked in frames. The frame is created when it is called, and it is deleted when the routine ends. Each frame contains:
- The return address
- The parameters of the routine
- Local variables
-
Heap: Dynamic space of memory that is allocated when data is created and deallocated when it is deleted. Usually here we find the objects.
Concurrency application
Programming allows us to implement concurrency in various ways depending on the language and development context. Here are possible use cases:
- On a UI, perform operations in a separate worker that does not block the interface.
- Implement alarms and timers.
- Implementation of parallel algorithms.
- Implement tasks from multiple concurrent clients, accessing shared resources.
Concurrency models
A task can be characterized, according to its type of activity, as:
- CPU-bound: It is a task that needs the CPU to perform intensive calculations.
- I/O-bound (Input/Output): This is a task that is usually waiting for an input/output operation, such as reading or writing to disk or the network.
Scheduler task assignment can be of two types: cooperative or preemptive.
- Cooperative: tasks manage their life cycle, and decide when to leave the worker.
- Preemptive: The scheduler allocates a time slice for the task, and takes it from the worker when it is fulfilled.
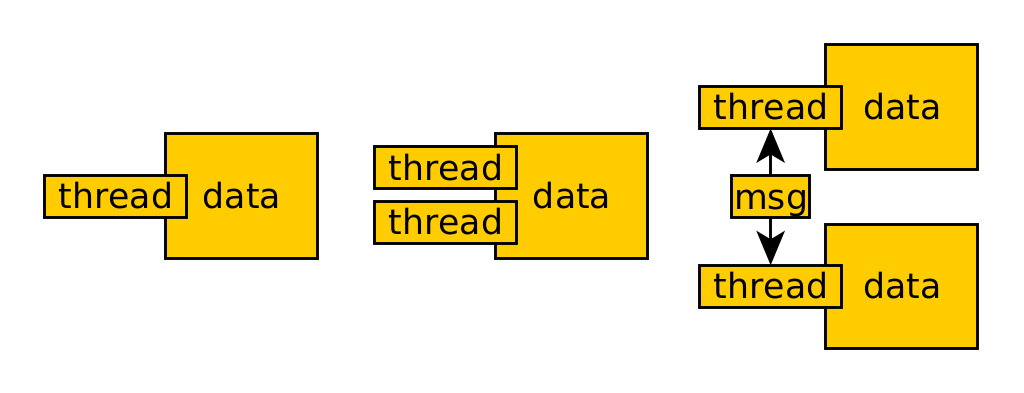
The main challenge to implement concurrency is the correct coordination between tasks and the access to shared resources in a safe way. These are some of the available approaches:
- Single Threaded: we only have one thread that is shared between all tasks.
- Shared State (or shared memory): Two or more tasks share a state that they can all read and write to, and various mechanisms allow this to be done safely.
- Message Passing: Nothing is shared. Instead, messages are exchanged.
The following diagram shows the single-threaded, shared-memory, and message-passing models.
Single Threaded
This option simplifies concurrency design, as there is no need to use mechanisms to manage simultaneous access to shared resources. It has the disadvantage that tasks cannot be parallelized, but this is only a problem if they are CPU-bound.
A common example is the UI event loop. It is implemented with a queue that receives events and handles them quickly, since they only perform asynchronous operations.
Shared State
Concurrent tasks interact by reading and writing shared and mutable objects in memory. It is complex as you need to implement locking mechanisms to coordinate the threads.
Let's imagine that threads A and B use the same code to share mutable objects. This code, which allows multiple threads to access it simultaneously in a safe manner, is called "thread-safe".
There are four strategies we'll look at: confinement, immutability, thread-safe data type and synchronization.
Message Passing
Concurrent tasks interact by sending messages to each other (1:1 or N:1) through a communication channel. Tasks send messages with immutable objects, and incoming messages from each task are queued for handling. They can do this synchronously or asynchronously, depending on whether you wait until you receive the response or not.
Message passing can be implemented at two levels: between threads of the same process (i.e. queues and producer/consumer) or between processes in a network (i.e. using sockets).
Shared State
The design of concurrent software that shares data is based on the idea that threads can access the same data, and that data can be modified by any thread.
An example of a language that uses this model is Java.
We have two challenges to solve:
-
The secure access to shared data. What mechanisms can we use to ensure threads safely access shared data?
-
The coordination between threads. How can we manage the execution order of threads, synchronize them when needed, and manage their interactions?
Secure access
If all threads have read-only access, no problem. The problem is when there is simultaneous read and write access.
There are two problematic situations: thread interference and data consistency.
Thread interference
Interference occurs when two operations, running on different threads, but acting on the same data, are intertwined. This means that the two operations consist of multiple steps and the step sequences overlap. This phenomenon is also called race condition.
For example: The increment operation of a counter consists of reading the current value, incrementing it, and writing the new value. If two increment operations are executed simultaneously, the final result may be erroneous.
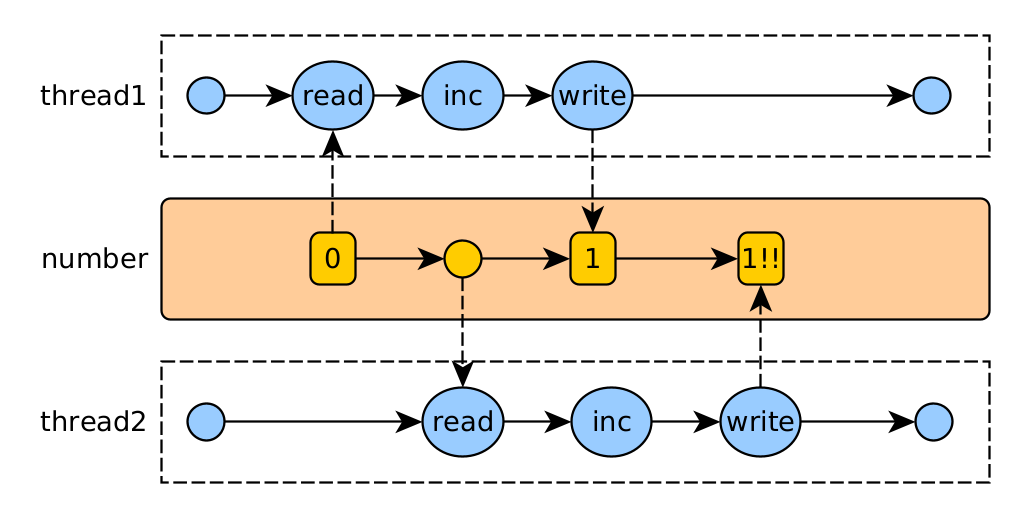
The solution is to synchronize access to the shared data, making each operation run atomically.
Data consistency
The problem is that two operations, running in different threads, but acting on the same data, do not see the changes that have been made to the data. This is because threads have a local copy of the shared data, and changes made by other threads are not seen.
For example, if one thread changes the value of a boolean variable and another thread reads the value, it may not see the change. This is because the compiler can optimize the code, and not read the value of the variable every time it is used, but instead saves it in a register. This prevents the thread from seeing changes made by other threads.
Strategies
Possible strategies to manage simultaneous access to shared data are: confinement, immutability, thread-safe types and synchronization.
- Containment. Do not share the variable between threads.
- Immutability. Make shared data immutable. All fields in the class must be final.
- thread-safe data type. We encapsulate shared data in an existing data type with security that performs coordination.
- Synchronization. Use synchronization to prevent threads from accessing at the same time by setting critical sections of code: pieces of code that access shared data and must be executed atomically.
Coordination
When designing your concurrent software flow, ask yourself these questions:
- You need to understand the solution to the problem. Usually, it starts from the sequential solution, to find the concurrent one.
- Consider whether can be parallelized. Some problems are inherently sequential.
- Think about the parallelization opportunities that dependencies between data allow. If there are no dependencies, we can decompose them and parallelize them.
- Find the places where the solution consumes the most resources, as candidates for parallelization.
- Decompose the problem into tasks, to see if these can be executed independently.
Here are some mechanisms available in different languages to coordinate threads:
- Create one or more tasks that will be executed in parallel.
- Let one thread wait for another to complete (join).
- That a thread notifies another that it has completed a task (notify).
- That a thread waits for another to notify it that it has completed a task (wait).
- For a thread to send an interrupt signal to another thread (interrupt).
Liveness of a multithreaded system
An application's liveness is its ability to run on time. The most common problems that can disrupt this vitality are:
- The deadlock: two or more threads are deadlocked forever, waiting for each other. It can happen if two threads block resources they need waiting for others to be free, which never will be.
- Starvation: the perpetual denial of the resources needed to process a job. An example would be the use of priorities, where the threads with the highest priority are always served, and the others never are.
- Livelock is very similar to deadlock, but threads do change their state, although the deadlock is never unlocked.
When a client makes a request to a server, the server must obtain exclusive access to the necessary shared resources. Correct use of critical sections will allow the system to have better vitality when the request load is high.
Java
Java is a high-level, object-oriented, compiled and interpreted programming language. Its programs are compiled to bytecode, which is interpreted by the Java Virtual Machine (JVM). This virtual machine is a process that is responsible for managing memory and its threads of execution.
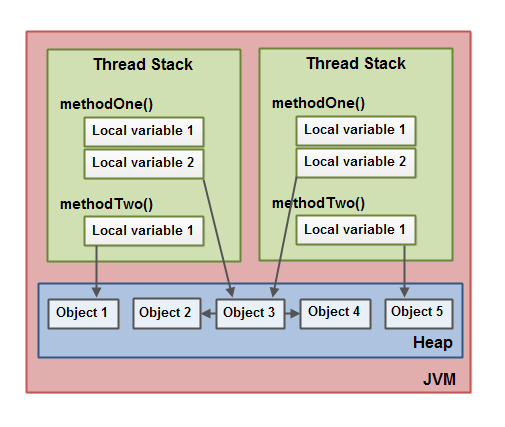
Java's call stack can contain primitive data and object references. Objects are stored on the heap, and the Garbage Collector is responsible for managing their memory.
The Java language implements concurrency using the shared state model and threads.
A Java application can create additional processes using ProcessBuilder. This class allows you to create system processes (Process) and run- them, stop them, read their output, redirect it, etc. In short, it allows you to interact with other system processes other than the Java Virtual Machine.
However, Java bases its implementation of concurrency on the use of threads of execution, which we will see next. This can be implemented at two levels: the low-level API based on threads and the high-level concurrent objects.
Threads
Java's low-level API is based on the Thread, which can have a number of states .
- NEW: A thread that has not been started.
- RUNNABLE: A thread that is running in the JVM. It may not have the CPU.
- BLOCKED: A thread that is waiting to enter a synchronized block (waiting for a monitor lock).
- WAITING: A thread that waits indefinitely for another (wait, join operations).
- TIMED_WAITING: A thread that waits a certain time for another (sleep, wait, join operations).
- TERMINATED: A thread that has terminated. It cannot be executed again.
We can create a thread in two ways:
- Extend the Thread class and rewrite the "run" method ( better not to use this method).
- Implement the Runnable interface and its "run" method. Then create a Thread by passing this object to the constructor:
new Thread(new MyRunnable())
Once we have the Thread, we can run it using its start() method, which will change its state from NEW to RUNNABLE.
For the examples we will see below, we will use the following utility class:
public class Threads {
private static long start = System.currentTimeMillis();
public static void log(String message) {
System.out.println(String.format("%6d %-10s %s",
System.currentTimeMillis() - start,
Thread.currentThread().getName(), message));
}
public static void spend(long millis) {
long startTime = System.currentTimeMillis();
while (System.currentTimeMillis() - startTime < millis);
}
public static void rest(long millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
Its methods can be called after doing an import static Threads.*;.
Below we can see an example of creating a thread called "thread" from the main thread, "main". Shows the state of the "child" thread before and after its execution.
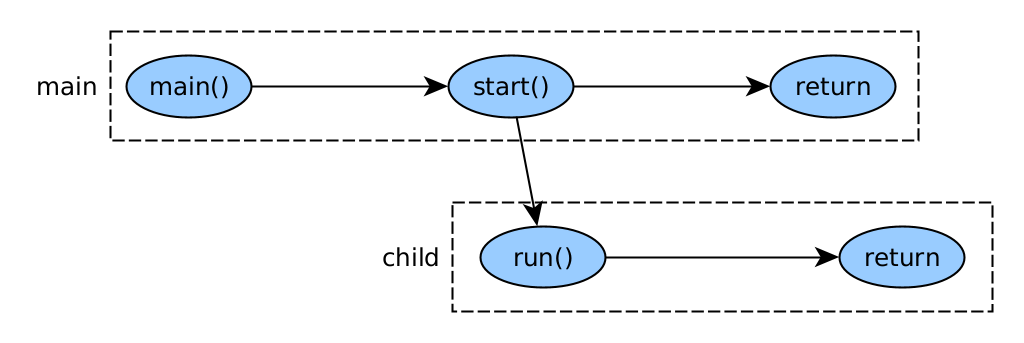
This would be the code:
public class StatesThread {
static class MyRunnable implements Runnable {
@Override
public void run() {
log("spending");
spend(750);
log("resting");
rest(750);
log("ending");
}
}
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable(), "child");
log(thread.getState().name());
thread.start();
rest(250);
log(thread.getState().name());
rest(875);
log(thread.getState().name());
rest(500);
log(thread.getState().name());
}
}
This could be a possible console output:
0 main NEW
8 child spending
258 main RUNNABLE
758 child resting
1133 main TIMED_WAITING
1508 child ending
1633 main TERMINATED
This example presents no difficulties as no data is shared. No synchronization mechanism is used between the two threads either.
Design techniques
There are basically four techniques to make sure we won't have problems accessing variables in shared memory. These are, in order of preference:
- Containment. Do not share objects between threads.
- Immutability. Make shared data immutable. All fields in the class must be final.
- Use thread-safe data types. We encapsulate shared data in an existing data type with security that performs coordination.
- For example, the package java.util.concurrent also contains some concurrent map, queue, set, list, and atomic variable classes. These classes can be used and shared without fear of causing race conditions.
- Synchronization. Use synchronization to prevent threads from accessing at the same time.
- monitor objects are objects that can only be accessed by one thread at a time. These allow you to define critical sections of code. It is the most used method.
- You can also use the reentrant locks (lock / unlock).
Next we will see an example of race condition, the most representative problem of shared state between threads. Two threads try to increment a counter on a shared object. The end result is not what we expect:
public class RaceThread {
static class SharedObject {
int counter;
}
static class MyRunnable implements Runnable {
SharedObject so;
MyRunnable(SharedObject so) {
this.so = so;
}
void increment() {
so.counter ++;
}
@Override
public void run() {
for (int i=0; i<1_000_000; i++) {
increment();
}
}
}
public static void main(String[] args) throws InterruptedException {
SharedObject so = new SharedObject();
Thread t1 = new Thread(new MyRunnable(so));
Thread t2 = new Thread(new MyRunnable(so));
t1.start();
t2.start();
t1.join();
t2.join();
log("counter is " + so.counter);
}
}
In this example, the increment() method is not thread-safe. The result is that the value of counter is not what we expected. This is because the increment() method is not atomic. This means that it is not a single operation, but is broken down into several smaller operations. In this case, the compiler breaks the increment() method into three operations:
- Read the value of
counterfrom memory. - Increase the read value.
- Write the incremented value to memory.
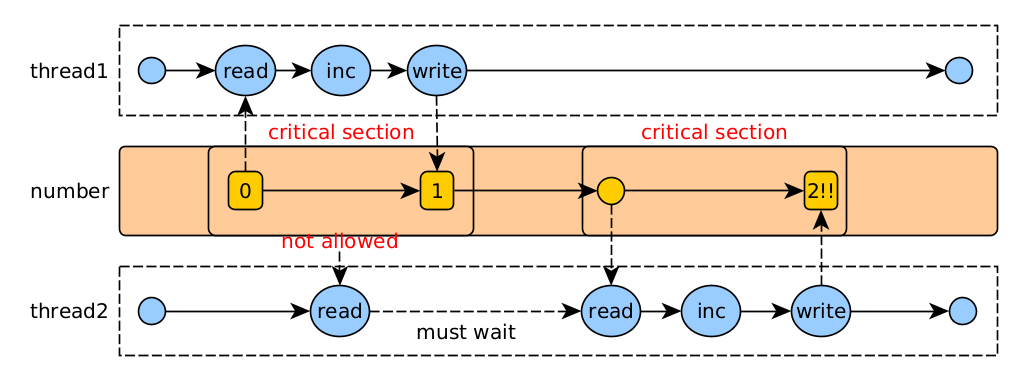
To synchronize, we need to define the concept of monitor (lock): a monitor is an object that can only be accessed by a single thread at the same time. In our problem, the monitor would be the so object. Each thread must acquire the monitor before accessing the counter variable. This is done with the synchronized keyword.
A first solution would be to disallow direct access to the counter field of the so object. In this case, the counter field would be private and could only be accessed through methods. These methods would be synchronized:
static class SharedObject {
private int counter;
synchronized void increment() {
counter++;
}
synchronized int getCounter() {
return counter;
}
}
A second solution would be to make it impossible for two threads to access the counter variable at the same time. This is done in Java using a monitor (lock). The increment() method would look like this:
void increment() {
synchronized (so) {
so.counter++;
}
}
When we create critical sections of code with Java's mechanisms we can order the events that occur. Ordering rules are explained with the concept of "happens-before". In short, if an event A occurs before an event B, then B cannot occur before A. This allows us to ensure that the events occur in the order we want.
There is a major difficulty in designing thread-safe code, in other words, that is safe from multiple thread access. Tests can be prepared for our code to see if a large number of threads running our code concurrently causes problems. But it is not always easy to simulate this situation.
If we look at the Java Standard Edition documentation, we see that the condition is sometimes referred to as " thread-safe" of the classes.
For example, in the class java.util.regex.Pattern is called:
- Instances of this class are immutable and are safe for use by multiple concurrent threads. Instances of the
Matcherclass are not safe for such use.
It is important when designing our code to be aware of whether we need more than one thread to access. And if so, design the class accordingly and document it.
Join, interrupt and volatile
Join
A join causes one thread to wait for another thread to complete. The joining thread goes into the WAITING state until the waiting thread finishes. If the waiting thread has already finished, the join does nothing.
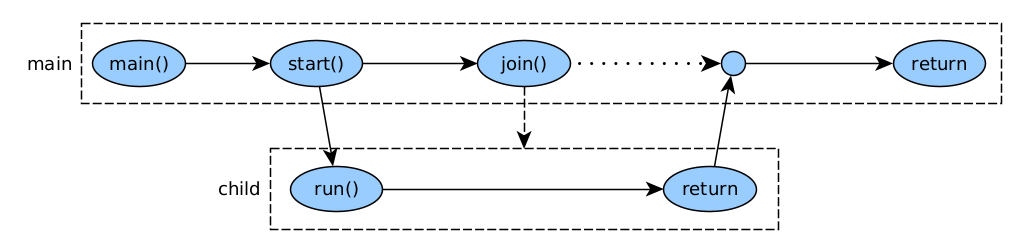
public class JoinThread {
static class MyRunnable implements Runnable {
@Override
public void run() {
log("starting");
spend(1500);
log("ending");
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new MyRunnable(), "child");
log("starting");
thread.start();
log("started");
thread.join();
log("joined");
}
}
Interrupted
An interrupt is an indication to a thread that it should stop doing what it is doing and do something else. Threads have a flag indicating whether they have been interrupted or not. There are two ways to check if a thread has been interrupted:
- That the thread makes frequent calls to methods that throw InterruptedException. For example, Thread.sleep(). Also useful if the interrupt occurred before sleep().
- Have the thread frequently check Thread.currentThread().isInterrupted().
Once the check is done and the break is detected, the thread's break flag is set back to `false' and a decision must be made about what to do. Usually what it will do is terminate its execution, but it doesn't have to. If nothing is done, the thread will continue to run.
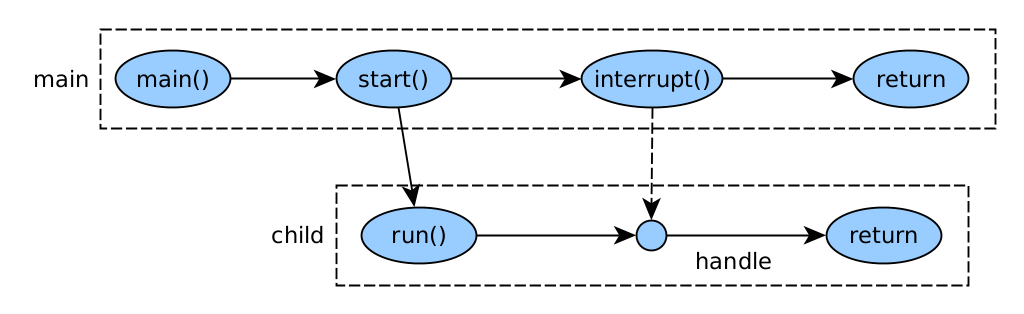
public class Interrupt1Thread {
static class MyRunnable implements Runnable {
@Override
public void run() {
log("starting");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
log("interrupted!");
}
log("ending");
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new MyRunnable(), "child");
log("starting");
thread.start();
log("started");
thread.interrupt();
thread.join();
log("joined");
}
}
public class Interrupt2Thread {
static class MyRunnable implements Runnable {
@Override
public void run() {
log("starting");
while (!Thread.currentThread().isInterrupted());
log("ending");
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new MyRunnable(), "child");
log("starting");
thread.start();
log("started");
rest(1500);
thread.interrupt();
thread.join();
log("joined");
}
}
Shared status
A thread can be terminated by sharing a variable that one thread modifies and the other thread reads. In Java, the variable must be defined as `volatile', indicating that changes made in one thread are visible in the rest. Alternatively, use safe objects created by us (sync mechanisms) or from a safe library (eg Java's atomic).
The volatile keyword should only be used if one thread is writing and the other (or others) are reading. If multiple threads are writing and reading, this needs to be handled as critical sections.
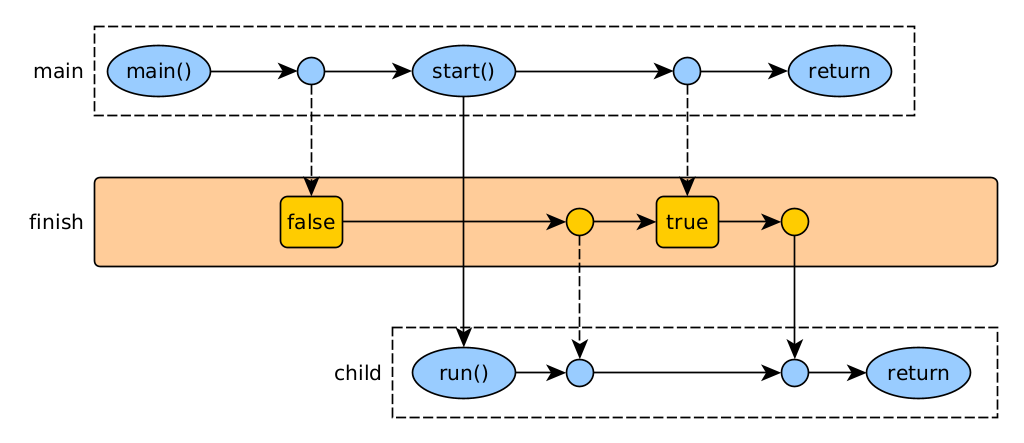
public class VolatileThread {
static class SharedObject {
boolean done; // volatile keyword needed
}
static class MyRunnable1 implements Runnable {
SharedObject so;
MyRunnable1(SharedObject so) {
this.so = so;
}
@Override
public void run() {
spend(1500);
so.done = true;
}
}
static class MyRunnable2 implements Runnable {
SharedObject so;
MyRunnable2(SharedObject so) {
this.so = so;
}
@Override
public void run() {
boolean done = false;
while (!done) {
done = so.done;
}
}
}
public static void main(String[] args) throws InterruptedException {
SharedObject so = new SharedObject();
Thread t1 = new Thread(new MyRunnable1(so));
Thread t2 = new Thread(new MyRunnable2(so));
t1.start();
t2.start();
t1.join();
log("joined 1 with " + so.done);
t2.join();
log("joined 2 with " + so.done);
}
}
Sincronization
Monitors (intrinsic lock)
In Java, synchronization is done using monitors. A monitor is any object that can have a single thread owner. Any thread can claim ownership of a monitor and in return access a critical section of restricted code. If there is already an owner, it must be waited until it ceases to be so.
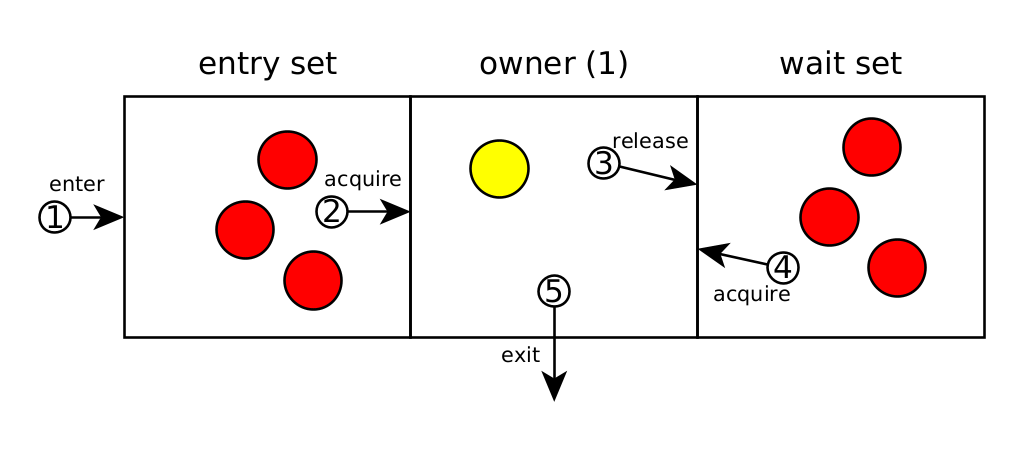
To request ownership of a monitor and access to the critical code section, we can use the "synchronized" reserved word. Depending on where we do it, the monitor object changes:
- instance methods: The monitor object is the instance. So only one thread per instance.
- class methods: The monitor object is the class. So only one thread per class.
- Blocks of code: the monitor object must be given inside the parentheses. Any object can be a monitor (eg
new Object()), although we usually make the monitor the same object we want to exercise access control over.
An example of instance methods:
public class SynchronizedCounter {
private int c = 0;
public synchronized void increment() {
c++;
}
public synchronized void decrement() {
c--;
}
public synchronized int value() {
return c;
}
}
Consequences:
- First, it is not possible for two threads to call two synchronized methods simultaneously. Subsequent calls are suspended until the first thread finishes with the object.
- Second, when a synchronized method finishes, it establishes a happens-before relationship: subsequent calls will have the changes made visible.
Important: Within a synchronized block, you need to do the minimum possible work: read the data and if necessary, transform it.
An example of code blocks:
public class MsLunch {
private long c1 = 0;
private long c2 = 0;
private Object lock1 = new Object();
private Object lock2 = new Object();
public void inc1() {
synchronized(lock1) {
c1++;
}
}
public void inc2() {
synchronized(lock2) {
c2++;
}
}
}
This method allows for finer grain: there can be one thread in lock1's code area and another in lock2's.
Wait / Notify (guarded lock)
Let's imagine that we want to wait until a condition is met:
public void waitForHappiness() {
// Simple method, wastes CPU: never do that!
while (!happiness) {}
System.out.println("Happiness achieved!");
}
We can do this between threads using the classic wait and notify communication method, which allows:
- Wait until a condition involving shared data is true, i
- notify other threads that the shared data has changed, probably triggering a condition that other threads wait for.
The methods are:
- wait(): when called, the current thread waits until another thread calls notify() or notifyall() on this monitor.
- notify(): Wake up any thread of all the ones waiting on this monitor.
- notifyAll(): Wake up all threads that are waiting on this monitor.
The wait() and notify methods must be called from within a synchronized block for the monitor object.
Also, as discussed in Object, the method wait() must be inside a loop waiting for a condition:
// in one thread:
synchronized (monitor) {
while (!condition) {
monitor.wait();
}
}
// in the other thread:
synchronized (monitor) {
monitor.notify();
}
In our case:
synchronized (monitor) {
while (!happiness) {
monitor.wait();
}
}
...
synchronized (monitor) {
happiness = true;
monitor.notify();
}
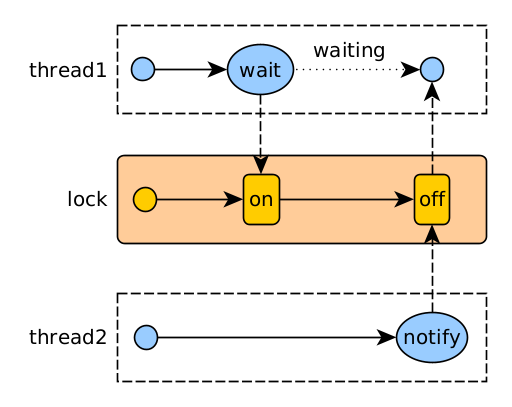
Operation of wait / notify (high level)
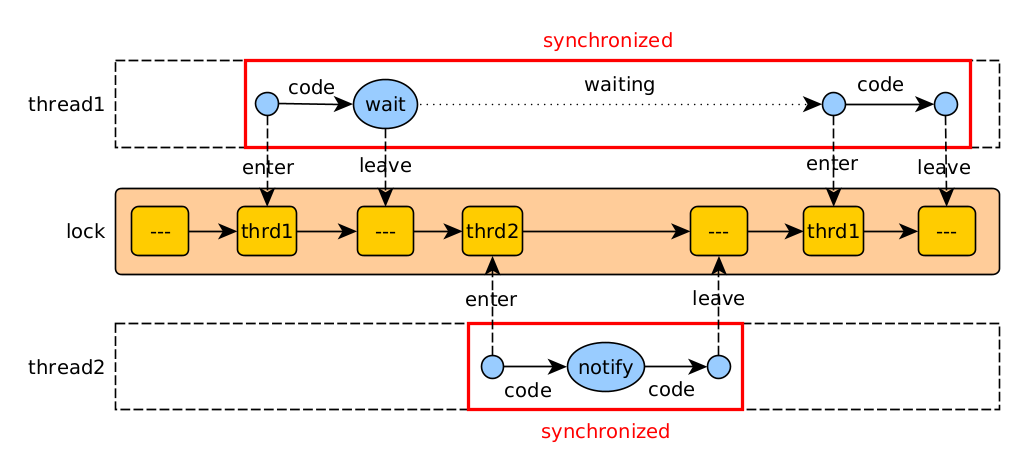
Operation of wait / notify (low level)
Reentrant Lock
Using synchronized is very simple and sufficient in many scenarios. But there is an implementation, ReentrantLock, that allows the following additional features:
- Lock attempt: allows you to try to lock a lock without having to wait.
- Fair locks: allow threads to finish executing in the order in which they requested the lock.
- Conditional locks: allow a thread to wait until a condition is met.
- Locks with interruption: allow a thread to wait until a condition is met, but can be interrupted.
static class MyRunnable implements Runnable {
SharedObject sound;
Lock lock;
MyRunnable(SharedObject so, Lock lock) {
this.sound = sound;
this.lock = lock;
}
void increment() {
try {
lock.lock();
so.counter ++;
} finally {
lock.unlock();
}
}
@Override
public void run() {
for (int i=0; i<1_000_000; i++) {
increment();
}
}
}
As you can see, the increment() method uses a lock to synchronize access to the shared variable. This is the same as using a synchronized method, but with the difference that we can use the lock in a block of code that can throw an exception.
Java concurrent library
The library java.util.concurrent contains classes useful when we do concurrency:
- Executors: The Executor interface allows you to represent an object that executes tasks. ExecutorService enables asynchronous processing, managing a queue and executing submitted tasks based on thread availability.
- Queues: ConcurrentLinkedQueue, BlockingQueue.
- Synchronizers: the classic Semaphore, CountDownLatch.
- Concurrent Collections: eg
ConcurrentHashMap, or the Collections methods /java/util/Collections.html)synchronizedMap(),synchronizedList()andsynchronizedSet(). - Variables that allow non-blocking atomic operations in the java.util.concurrent.atomic package: AtomicBoolean, AtomicInteger, etc.
It is always preferable to use these classes over wait/notify synchronization methods, because they simplify programming. Just like it's better to use executors and tasks than threads directly.
Tasks and executors
Most concurrent applications are organized using tasks. A task performs a specific job. In this way, we can simplify the design and operation.
We see a possible solution for managing connections to a server. Suppose we have a method, attendRequest(), which serves a web request.
Sequential execution
class OneThreadWebServer {
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
Socket connection = socket.accept();
attendRequest(connection);
}
}
}
One thread for each request
class OneThreadPerRequestWebServer {
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
Socket connection = socket.accept();
Runnable task = new Runnable() {
@Override
public void run() {
attendRequest(connection);
}
}
new Thread(task).start();
}
}
}
Shared group of threads
class ExecutionTasksWebServer {
private static final int NTHREADS = 100;
private static final Executor executor = Executors.newFixedThreadPool(NTHREADS);
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
final Socket connection = socket.accept();
Runnable task = new Runnable() {
public void run() {
attendRequest(connection);
}
};
executor.execute(task);
}
}
}
In this solution we introduced the Executor interface:
public interface Executor {
void execute(Runnable command);
}
It is an object that allows running Runnables. Internally, what it does is execute tasks asynchronously, creating a thread for each running task, and returning control to the thread that calls its execute method. Tasks can have four states:
- Created
- Sent
- Started
- Completed
Executors can be created from the class with static methods Executors. This class returns a subclass of Executor, the ExecutorService . This subclass uses the Thread Pool pattern, which reuses a maximum number of threads between a number of tasks in a queue.
An ExecutorService must always be stopped with the shutdown() method, which stops all threads in the pool.
Tasks with results
Some tasks return results. To implement them, we can use the interfaces Callable and Future:
public interface Callable<V> {
V call() throws Exception;
}
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException, CancellationException;
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, CancellationException, TimeoutException;
}
Callable<V> allows to execute the task and return a value of type V. In order to be able to execute it, we need an ExecutorService. In particular, its two methods:
Future<?> submit(Runnable task)<T> Future<T> submit(Callable<T> task)
These allow a Runnable / Callable to be executed and return a Future, which is an object that allows the result to be obtained in a deferred manner using the get() method (blocking) or get(long timeout, TimeUnit unit) (blocking for some time).
We can also cancel the task using cancel(boolean mayInterruptIfRunning): the parameter tells whether to interrupt also if it has already started.
ExecutorServices can be created using the same class we saw before, Executors.
Below is a working example. How does execution change if we do Executors.newFixedThreadPool(2)?
public class SimpleCallableTest {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(1);
Future<String> f1 = executor.submit(new ToUpperCallable("hello"));
Future<String> f2 = executor.submit(new ToUpperCallable("world"));
try {
long millis = System.currentTimeMillis();
System.out.println("main " + f1.get() + " " + f2.get() +
" in millis: " + (System.currentTimeMillis() - millis));
} catch (InterruptedException | ExecutionException ex) {
ex.printStackTrace();
}
executor.shutdown();
}
private static final class ToUpperCallable implements Callable<String> {
private String word;
public ToUpperCallable(String word) {
this.word = word;
}
@Override
public String call() throws Exception {
String name = Thread.currentThread().getName();
System.out.println(name + " calling for " + word);
Thread.sleep(2500);
String result = word.toUpperCase();
System.out.println(name + " result " + word + " => " + result);
return result;
}
}
}
In Java 7 the framework fork/join was introduced.
Java 8 introduced the CompletableFuture, which allows combine futures and better handle errors that occur. An example is the use of the complete method to complete a future, in another thread:
CompletableFuture<String> completableFuture = new CompletableFuture<>();
//...
String result = completeableFuture.get();
// while in another thread...
completableFuture.complete("Hello World!");
Or, the ability to run directly with supplyAsync:
Supplier<String> supplier = new Supplier<String>() {
@Override
public String get() {
return "Hello, world!";
}
};
Future<String> future = CompletableFuture.supplyAsync(supplier, executor); // executor is optional
System.out.println(future.get());
Message passing
- Synchronous and asynchronous programming model
- Asynchronous communication
- Synchronous request management
- Asynchronous management of requests
- Examples
- Programming and reactive systems
Message passing can be implemented:
- Within a process, via threads. Using buffers or queues, for example.
- Between processes. It is usually done using the client/server paradigm and through networks. A possible mechanism is the use of sockets, as can be seen in the UF Sockets and Services. In this communication there is no sharing of mutable data, but it can happen that multiple clients access the same server simultaneously.
A between processes implementation can be seen in the diagram.
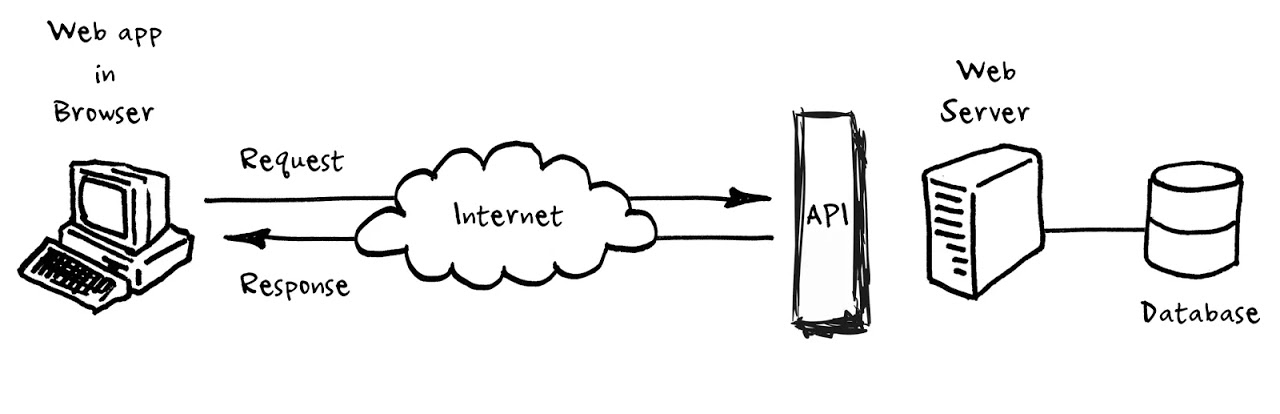
Synchronous and asynchronous programming model
Communication between the two parties can be synchronous or asynchronous, depending on whether there is an I/O (input/output) block.
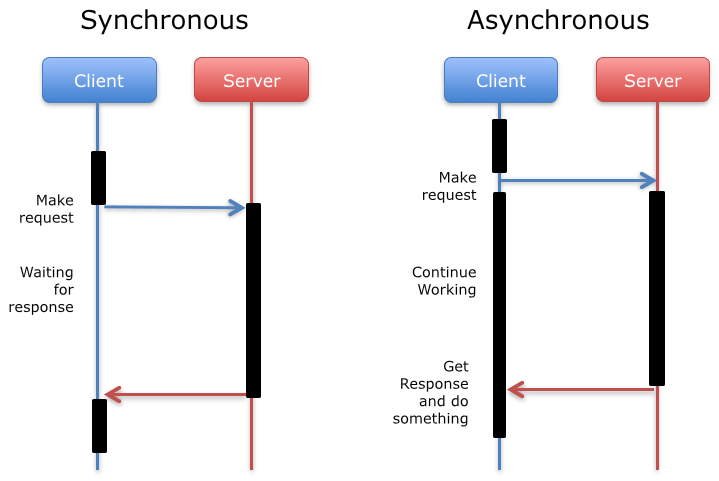
As you can see in the diagram, in the synchronous form the client waits for the response from the server (I/O blocking), and meanwhile does nothing. In the asynchronous form it sends the request, continues working, and at some point receives the response (no I/O blocking).
Which form is more convenient? It depends on the circumstances. The synchronous form is easier to implement, but the asynchronous allows to improve system performance by introducing concurrency.
Asynchronous communication
Asynchronous requests must allow the client to know the result afterwards. Some possible solutions:
- None: The client can only know the result by querying one or several times after (polling).
- A code call: When the request finishes, the server makes a code call. It could be implemented using callbacks.
- A message: When the request finishes, the server sends a message that can be received by the client. This message can travel in different protocols, and is usually implemented using some kind of middleware. Messages typically end up in queues, which are then managed by servers.
Synchronous request management
When we use the synchronous model (with blocking), a single thread cannot handle multiple simultaneous requests. This means we need to create a thread to handle each request and return the response. We call it thread-based architecture.
Usually, the number of threads that are allowed to be managed simultaneously is limited to avoid excessive consumption of resources.
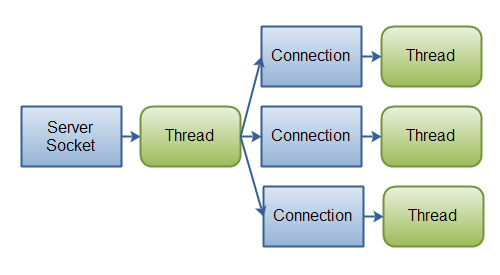
Asynchronous management of requests
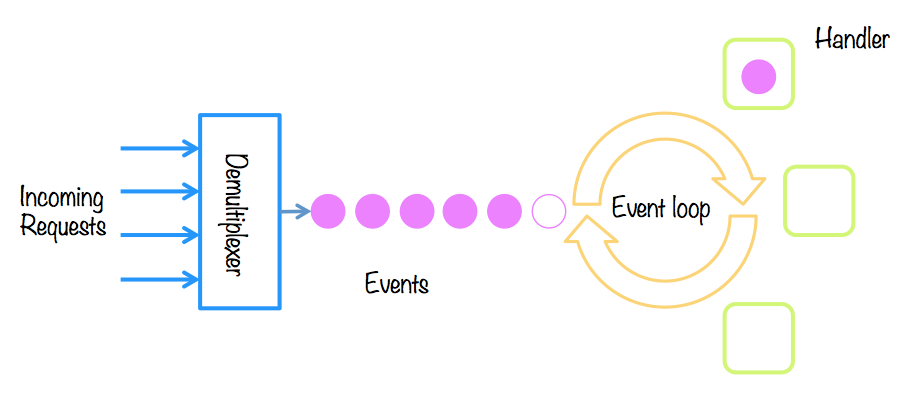
The producer-consumer pattern is reproduced: the producers are the origin of the events, and only know that one has occurred; while the consumers need to know that there is a new event, and they must attend to it (handle). We call it event-based architecture.
Some techniques to implement the service:
- The reactor pattern: requests are received and processed synchronously, in the same thread. It works if requests are processed quickly.
- The proactor pattern: requests are received and processing is split asynchronously, introducing concurrency.
In Java we have Vert.x, a multi-reactor implementation (with N event loops).
Another technique for handling asynchronous requests is the actor model. This model allows concurrent programs to be created using non-concurrent actors.
- An actor is a lightweight, decoupled unit of computation.
- Actors have state, but cannot access the state of other actors.
- Can communicate with other actors using immutable asynchronous messages.
- The actor processes messages sequentially, avoiding contention on state.
- Messages may be distributed over the network.
- No specific order is assumed in the messages.
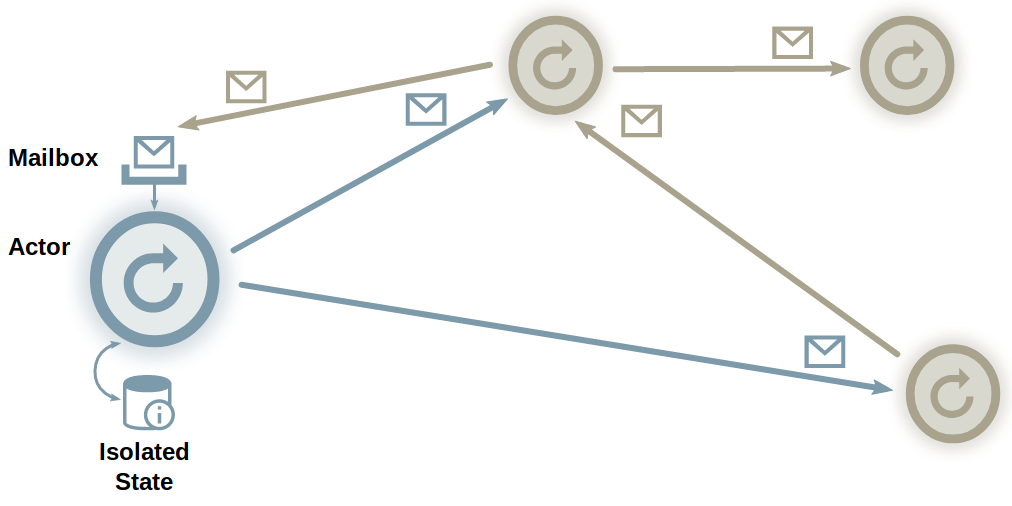
In Java, we have an example library: Akka.
Examples
One way to implement it is to pass messages between threads by using a synchronized queue. There may be one or more producers and one or more consumers. The queue must be thread-safe. In Java, the BlockingQueue implementations, ArrayBlockingQueue and LinkedBlockingQueue, are examples. Objects in these queues must be of an immutable type.
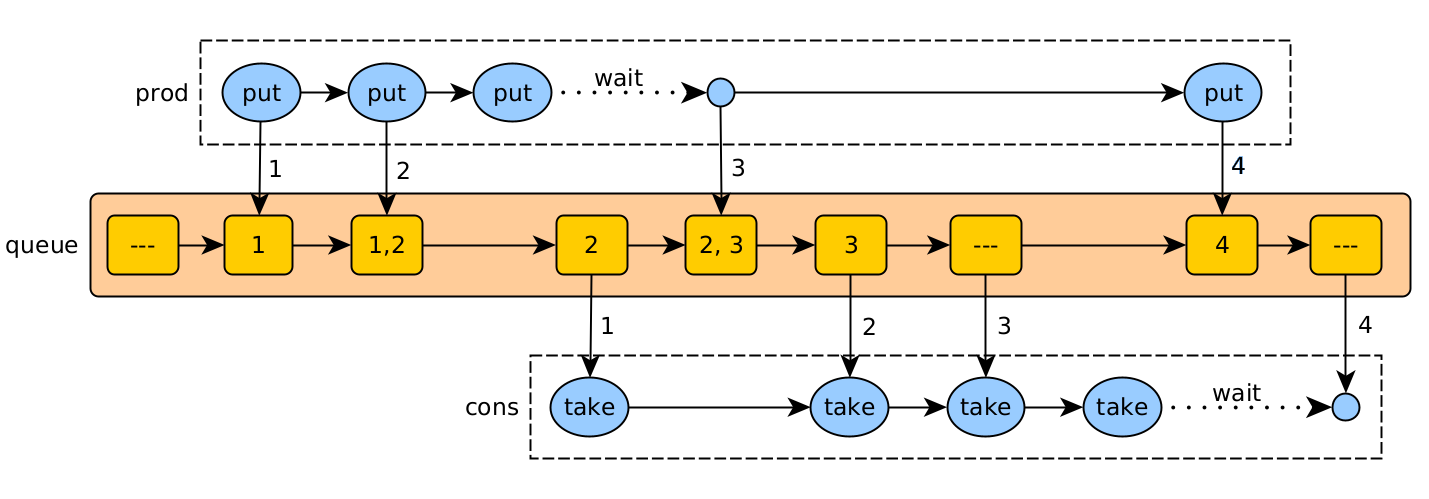
Asynchronous buffer (queue)
In this example, a producer thread sends jobs (1, 2, 3, 4) to a consumer thread using a thread-safe queue. The maximum queue size is 2.
The actions are:
- put (prod): add a job, waiting if there is not enough space.
- take (cons): read a job for processing, and wait if there is none.
Asynchronous printer call flow
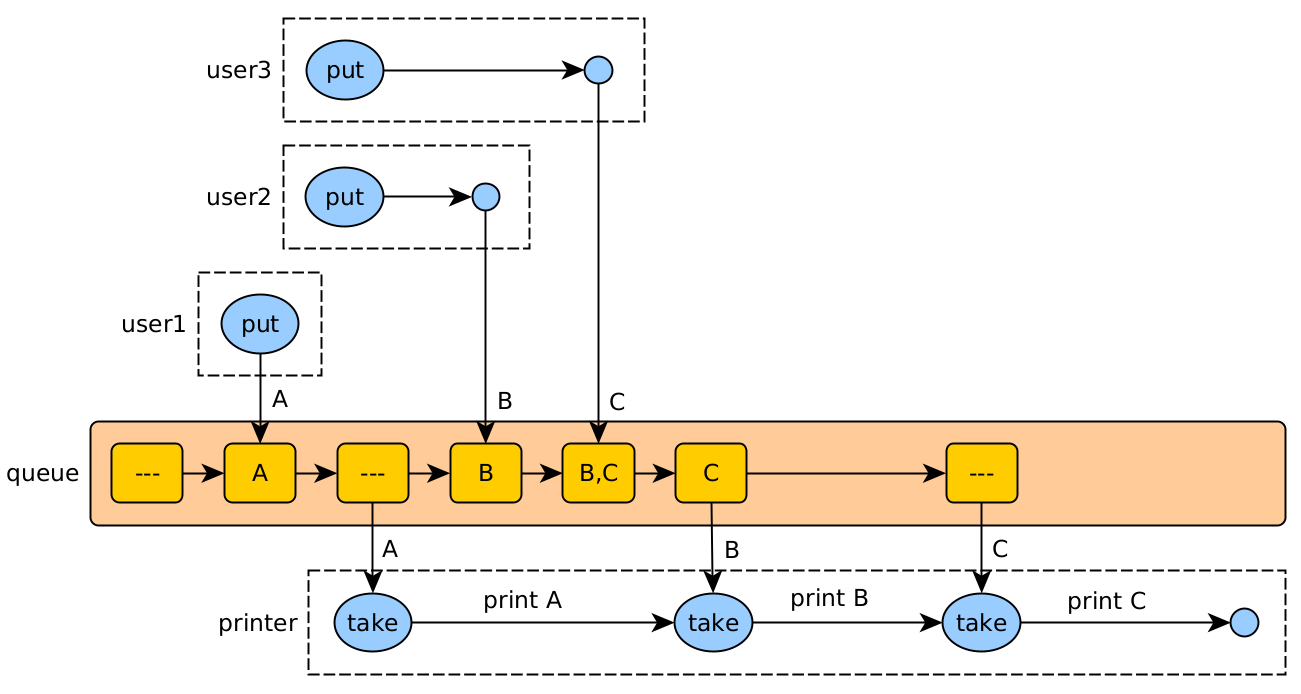
Sometimes requests refer to a shared resource that is not allowed to be used by more than one client at a time. In these cases, you can implement a queue that handles requests asynchronously:
- The client makes the asynchronous request, and later can receive the response or confirmation of the request.
- The server registers the request in a queue, which is served in order by a separate thread.
The printer is a single thread (server) that reads the jobs added to the queue by different users (threads), and attends to them.
We could also have more than one queue, if there is the possibility of having more than one point to serve the requests (several printers).
Programming and reactive systems
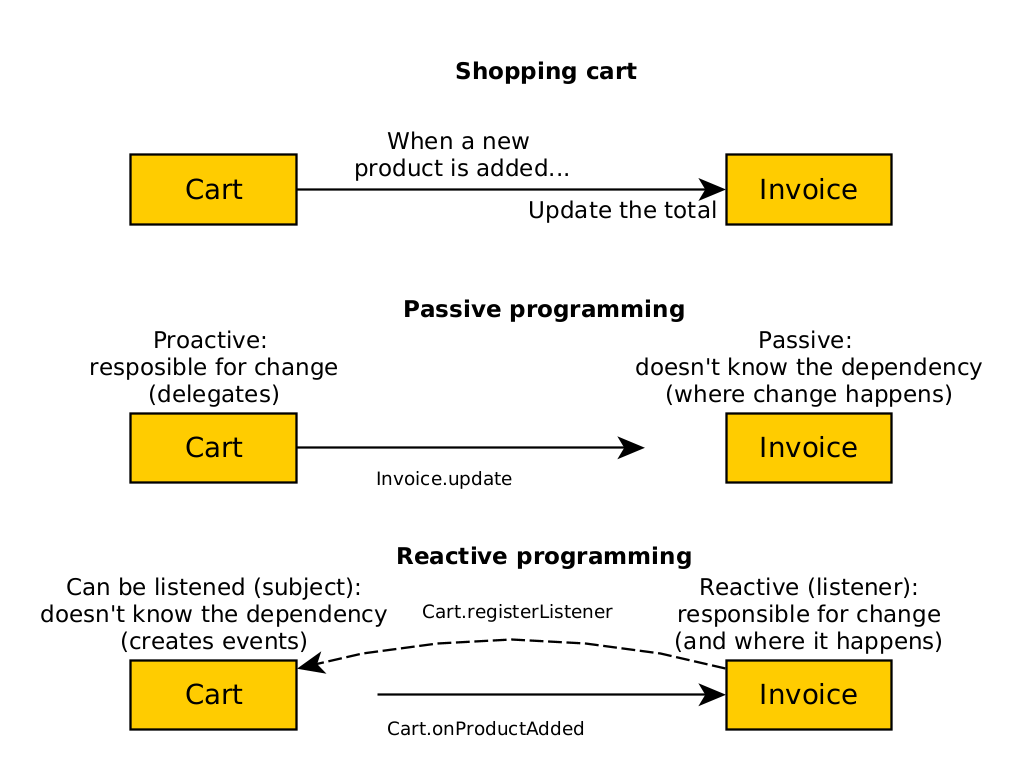
passive programming is traditional in OO designs: one module delegates to another to produce a change to the model.
The proposed alternative is called reactive programming, where we use callbacks to invert responsibility.
The term "reactive" is used in two contexts:
- reactive programming is based on events (event-driven). An event allows the registration of several observers. It usually works locally.
- reactive systems are generally based on messages (message-driven) with a single destination. They most often correspond to distributed processes that communicate over a network, perhaps as cooperating microservices.
In the shopping cart example, we can see how to implement this with passive and reactive programming:
- With passive, the basket updates the invoice. Therefore, the basket is responsible for the change and depends on the invoice.
- With reactive, the invoice receives a product added event and updates itself. The invoice depends on the basket, as it has to tell it that it wants to hear its events.
Pros and cons:
- Reactive programming allows you to better understand how a module works: you only need to look at its code, since it is responsible for itself. With the passive it is more difficult, since you have to look at the other modules that modify it.
- On the other hand, with passive programming it is easier to understand which modules are affected: by looking at which references are made. With reactive programming you need to look at which modules generate a certain event.
reactive programming is asynchronous and non-blocking. Threads looking for shared resources do not block waiting for the resource to become available. Instead, they continue their execution and are notified later when the service is complete.
Reactive extensions allow imperative languages, such as Java, to implement reactive programming. They do this using asynchronous programming and observable streams, which emit three types of events to their subscribers: next, error, and completed.
Since Java 9 reactive streams have been defined using the Publish-Subscribe (very similar to the observer pattern) using the Flow. The most widely used implementations are Project Reactor (e.g. Spring WebFlux) and RxJava (e.g. Android).
On the other hand, a reactive system is a style of architecture that allows several applications to behave as one, reacting to their environment, keeping track of each other, and allowing their elasticity, resilience and responsiveness, usually based on queues of messages directed to specific receivers (see the Reactive Manifesto). An application of reactive systems are microservices.
Both the reactor/proactor patterns and the actor model allow implementing reactive systems.
Sockets and Services
Learning results:
- Program network communication mechanisms using sockets and analyzing the execution scenario.
- Develop applications that offer network services, using class libraries and applying efficiency and availability criteria.
References
- OSI Model
- HTTP (Mozilla)
- HttpURLConnection
- reqbin.com
- A guide to Java sockets
- Do a Simple HTTP Request in Java
- Core Java Networking (eugenp)
- Read an InputStream using the Java Server Socket
- REST vs Websockets (baeldung)
- A Guide to the Java API for WebSocket (baeldung)
- All About Sockets (The Java Tutorials)
- SSL Handshake Failures (baeldung)
- HTTP: The Protocol Every Web Developer Must Know (part 1)
- HTTP: The Protocol Every Web Developer Must Know (part 2)
- REST API Tutorial
- Blocking I/O and non-blocking I/O
- A Guide to NIO2 Asynchronous Socket Channel
- Java NIO Tutorial (Jenkov)
- How Single-Page Applications Work
- How Single-Page Web Applications actually work?
- What Is a Single Page Application and Why Do People Like Them so Much?
- Guía práctica para la publicación de Datos Abiertos usando APIs
- Local-first software
Protocols
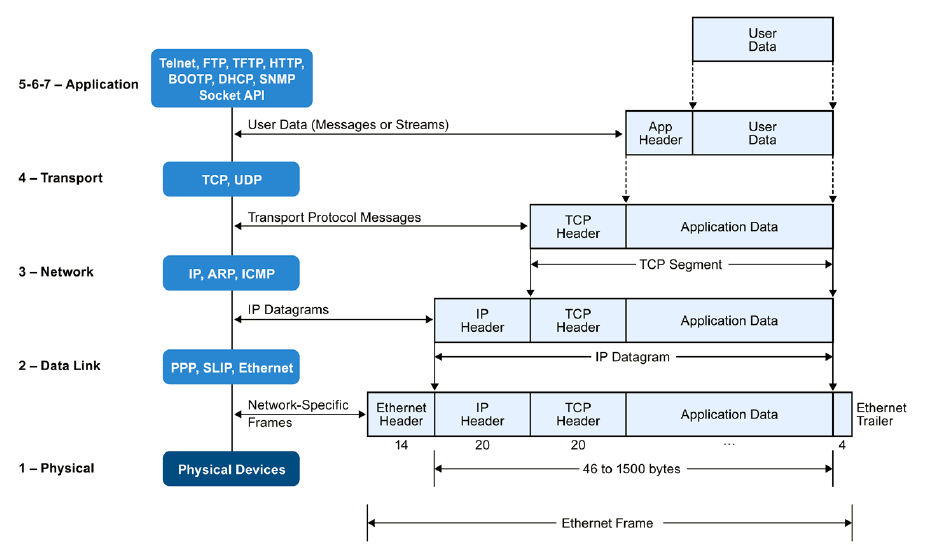
Internet protocols have more than one model. The OSI model gives us a layered organization:
- Physical: transmission and reception of bits on the physical medium.
- Link: reliable transmission of frames between two nodes. PPP.
- Network: transmission of packets over a multi-node network, with addressing, routing and traffic control. IP
- Transport: transmission of data segments between points in a network. TCP, UDP.
- Session: session management.
- Presentation: translation of the protocols towards an application. MIME, SSL
- Application: High level APIs. HTTP, Websockets.
As programmers, we can get involved at different levels of the model:
- Building protocols based on TCP, UDP using Java Sockets (level 4 and a half).
- Accessing HTTP (layer 7) web applications, implemented on ports 80 or 443 (secure).
Standard layer 4 and half protocols can be seen in this list.
IP version 4
IPv4 addresses use 32 bits, and have ranges assigned for different purposes:
- Class A: from 1.x.x.x to 127.x.x.x (subnet mask 255.0.0.0). The range 127.x.x.x is reserved for the loopback.
- Class B: from 128.0.x.x to 191.255.x.x (subnet mask 255.255.0.0).
- Class C: from 192.0.0.x to 223.255.255.x (subnet mask 255.255.255.0).
- Class D: from 224.0.0.0 to 239.255.255.255. Reserved for multicasting.
- Class E: from 240.0.0.0 to 255.255.255.254. Reserved for research.
Of these, private IPs are considered:
- 10.0.0.0 to 10.255.255.255
- 172.16.0.0 to 172.31.255.255
- 192.168.0.0 to 192.168.255.255
These are the types of routing available:
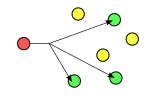
Unicast: Class A, B and C addresses. TCP and UDP transport.
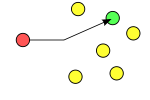
Broadcast: Host address with all 1's. UDP transport. They do not go through routers, and are received by all machines.
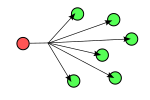
Multicast: Class D addresses. UDP Transport. A machine must listen to receive communication. Available on local networks.
IP version 6
IPv6 is version 6 of the Internet Protocol (IP), and is designed to replace the current IPv4 on the internet, but it is still not fully supported. Addresses use 128 bits, which are shown in groups of 4 hex digits:
xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx
IPv6 is classless. When subnetting, the notation /NN indicates the length of the network prefix. For instance:
2001:0db8:1234::/64
The notation '::' indicates one or more groups of value 0. There can only be one '::' in an address.
The loopback is represented as ::1/128 or, simply, ::1.
IPv6 routing types are unicast, multicast, and anycast (the broadcast type does not exist in IPv6). Anycast allows you to send a message to a group where only one, the closest one, answers.
HTTP Tools
We have three tools for debugging HTTP protocols: netcat, curl, and browser inspector.
Netcat allows you to connect to a port and have a conversation, using pipes. If -u is specified use UDP, otherwise TCP. For example, to access the echo service on our machine:
$ nc localhost 7
CURL allows you to get the response from a URL on the network.
$ curl -I http://maripili.es
(GET, veure headers)
HTTP/1.1 200 OK
Date: Fri, 05 Apr 2019 05:03:23 GMT
Server: Apache
X-Logged-In: False
P3P: CP="NOI ADM DEV PSAi COM NAV OUR OTRo STP IND DEM"
Cache-Control: no-cache
Pragma: no-cache
Set-Cookie: 4af180c8954a0d5a1965b5b1b23ccbc5=pc1jg8f5kqigd71iec5a5lm7k5; path=/
X-Powered-By: PleskLin
Content-Type: text/html; charset=utf-8
$ curl http://maripili.es
(GET, content of the web page)
$ curl -v http://maripili.es
(GET, headers i contingut)
$ curl -d "key1=val1&key2=val2" http://maripili.es/contacto/
(POST)
Introduction to HTTP
HTTP is an application-level protocol for collaborative and distributed systems. It is the main component of the web, thanks to the use of hypertext documents. HTTP/1.1, the current version, is implemented using TCP in the transport. Version 2 is already standardized, and version 3 will work over UDP.
The secure version of HTTP is called HTTPS, or HTTP over TLS, the cryptographic protocol for secure transmission.
Session
A session is a sequence of requests/responses. It starts by establishing a TCP connection to a port on a server (usually 80). The server usually responds with a code, of the type "HTTP/1.1 200 OK", and with a body, which usually contains the requested resource.
HTTP is a stateless protocol, although some applications use mechanisms to store information. For example, cookies.
Messages
A request usually contains:
- A request line, with a method. Example: GET /images/logo.png HTTP/1.1
- Request header fields. Example: Accept-Language: ca
- An empty line.
- An optional body. Example: to make a POST.
Request Methods:
- GET - The usual method for getting a resource. It has no body.
- POST - The method used to send a body to the server. Used in forms.
- PUT, DELETE, TRACE, OPTIONS, CONNECT, PATCH are other methods used.
A response contains:
- A status line. Example: HTTP/1.1 200 OK.
- Response header fields. Example: Content-Type: text/html
- An empty line.
- An optional body. Example: For a GET, the required content.
The status codes can be of the type:
- Information (1XX).
- Success (2XX). Example: 200 OK.
- Redirection (3XX). Example: 301 Moved Permanently.
- Client error (4XX). Example: 404 Not Found.
- Server error (5XX). Example: 500 Internal Server Error.
We can use the telnet program to connect to an HTTP web server and send a GET command.
$ telnet maripili.es 80
Trying 217.160.0.165...
Connected to maripili.es.
Escape character is '^]'.
GET / HTTP/1.0
Host: maripili.es
This causes the server to respond:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Connection: close
Date: Wed, 16 Feb 2022 08:12:31 GMT
Server: Apache
<!DOCTYPE html>
<html lang="es">
...
</html>
Connection closed by foreign host.
URL i HttpURLConnection
The URL class refers to a resource on the WWW. A generic resource can have the following form.

Let's see an example for the HTTP protocol:
https://www.example.com/test?key1=value1&key2=value2
In this case, we have to:
- scheme is https
- host is www.example.com
- port is 80, but is not specified as it is the default value in the HTTP protocol
- the path is test
- the query is key1=value1&key2=value2
In Java, a URL can be constructed with:
URL url = new URL(String spec)
Once this is done, we can access each part of the URL using the getHost(), getPath(), getPort(), getProtocol(), getQuery(), etc. methods.
The two most important methods for interacting with the URL are:
URLConnection openConnection(): Returns a connection to the remote resource.InputStream openStream(): Returns an InputStream to read the remote resource.
The class URLConnection is abstract, and if we have accessed an HTTP resource then the object will be an instance of HttpURLConnection.
openStream
To read a web page that is in the URL of a string called urlText, we can do:
URL url = new URL(urlText);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream()));
To read a file:
BufferedInputStream in = new BufferedInputStream(new URL(urlText).openStream());
openConnection
With openConnection we can access the methods of the HTTP protocol and the status codes that are returned or the content type.
This is a GET method:
URL url = new URL(urlText);
HttpURLConnection httpConn = ((HttpURLConnection) url.openConnection());
httpConn.setRequestMethod("GET"); // optional: GET is the default method
int responseCode = httpConn.getResponseCode();
String contentType = httpConn.getContentType();
BufferedReader in = new BufferedReader(new InputStreamReader(httpConn.getInputStream()));
// in reading is left: a response from the server
This is a POST method:
URL url = new URL(urlText);
HttpURLConnection httpConn = ((HttpURLConnection) url.openConnection());
httpConn.setRequestMethod("POST");
httpConn.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(httpConn.getOutputStream());
out.write("propietat1=valor1&propietat2=valor2"); // values for the POST parameters
out.close();
int responseCode = httpConn.getResponseCode();
String contentType = httpConn.getContentType();
BufferedReader in = new BufferedReader(new InputStreamReader(httpConn.getInputStream()));
// in reading is left: a response from the server
Sockets
- TCP and UDP
- Example protocol: ECHO
- Example protocol: SMTP
- TCP communication
- UDP communication
- Timers
- Closing
- Asynchronous communication
A socket is a two-way link that allows two software that are on the network to communicate.
These two softwares perform two functions: that of the client and that of the server. The server provides some service from a known location (IP address + port), and the client accesses this service. This service must implement a well-defined protocol, either a standard one or a custom-designed one.
The port numbers are:
- The range 0 to 1023 are well-known or system ports. In Linux, you need to be an administrator to have a service on these ports.
- The range 1024-49151 is the registered ports, assigned by IANA.
- The range 49152–65535 are dynamic or private, or short-lived ports.
Since both softwares work in the protocol realm, there are no dependencies on each other in the code of the two softwares. But it is common for whoever implements the protocol to provide a client library to be able to access the service. This reduces the code a client has to write, and ensures that it will use the protocol correctly. In Java, the client library is materialized through a jar file and usage documentation.
TCP and UDP
Either TCP or UDP protocols can be used. TCP is connection oriented, and UDP is not. This means that TCP requires a previous connection step between the client and the server in order to communicate. Once the connection is established, TCP ensures that the data reaches the other end or it will indicate that an error has occurred.
In general, packets that must pass in the correct order, without loss, use TCP, while real-time services where later packets are more important than older packets use UDP . For example, file transfer requires maximum accuracy, so it is usually done over TCP, and audio conferencing is often done over UDP, where momentary interruptions may not be noticeable.
TCP needs control packets to establish the connection in three phases: SYN, SYN + ACK and ACK. Each packet sent is answered with an ACK. And finally, a disconnection occurs from both sides with FIN + ACK and ACK.
UDP, on the other hand, only transmits the request/response packets, without any control over the transmission.
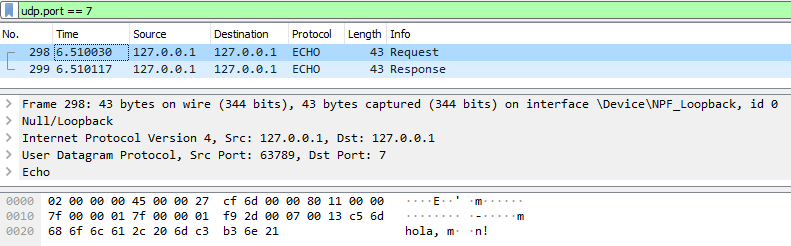
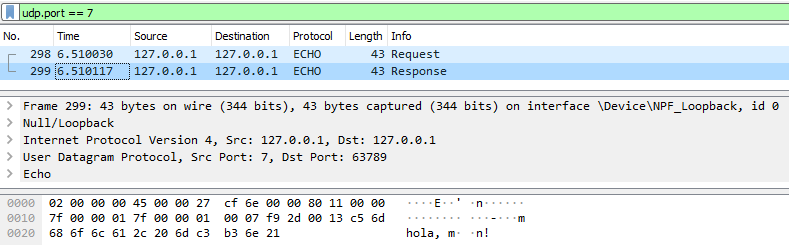
Example protocol: ECHO
Below is a visualization of the ECHO protocol using Wireshark, for both the TCP and UDP implementations.
TCP capture (request and response)
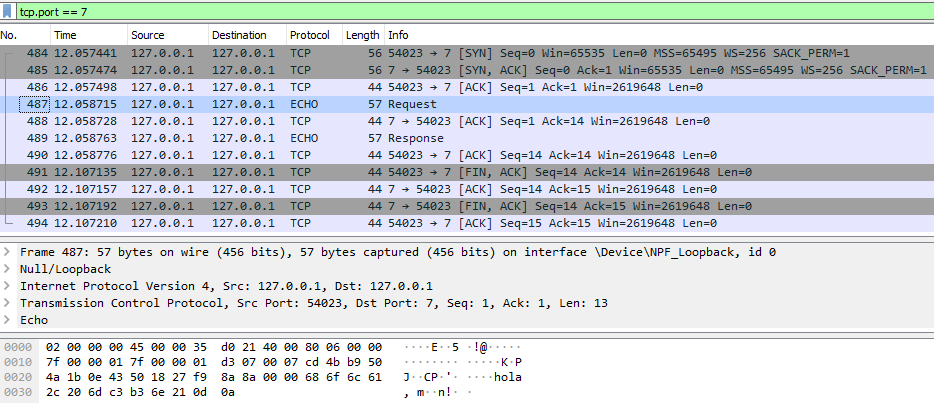
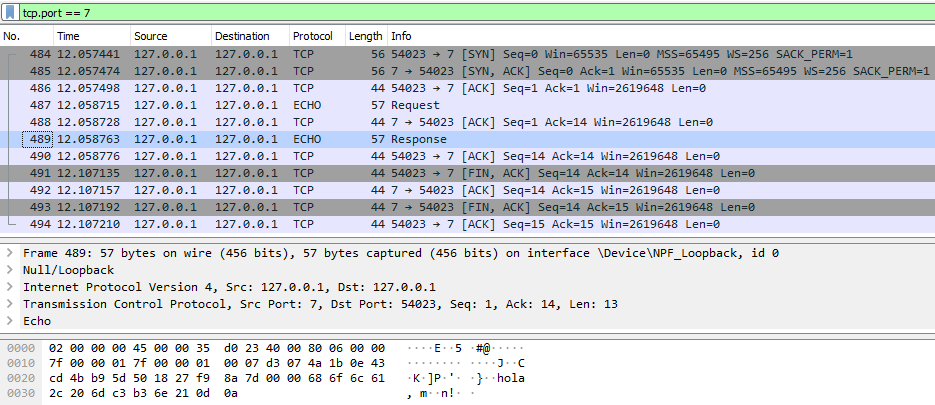
UDP capture (request and response)
Example protocol: SMTP
SMTP is a protocol that works on port 25, over TCP. The client sends commands, and the server responds with a status code.
Next we see a conversation (C: client / S: server). This entire conversation is held over an open connection.
C: <client connects to service port 25>
C: HELO snark.thyrsus.com the machine identifies itself
S: 250 OK Hello snark, glad to meet you the receptor accepts
C: MAIL FROM: <esr@thyrsus.com> identification of the sender
S: 250 <esr@thyrsus.com>... Sender ok receptor accepts
C: RCPT TO: cor@cpmy.com identification of the destination
S: 250 root... Recipient ok receptor accepts
C: DATA
S: 354 Enter mail, end with "." on a line by itself
C: Scratch called. He wants to share
C: a room with us at Balticon.
C: . end of the multiline message
S: 250 WAA01865 Message accepted for delivery
C: QUIT sender says goodbye
S: 221 cpmy.com closing connection receptor disconnects
C: <client hangs up>
TCP communication
Java has two classes in the java.net package that allow this:
Socket: implementation of the client socket, which allows two software to communicate on the network.ServerSocket: implementation of the server socket, which allows listening to requests received from the network.
The operation is reflected in the following two images: first the client requests a connection, and then the server accepts it, and it is established.


Server to uppercase
This server listens for lines of text and returns the uppercase version.
Communication begins with the client's connection request, and the server's acceptance. These two actions create a shared socket of type Socket, on which both the client and the server can use the methods:
getInputStream()getOutputStream()
The client can send text strings, which the server will convert to uppercase.
The protocol we invented states that communication ends when the client sends an empty line. to which the server responds with a goodbye.
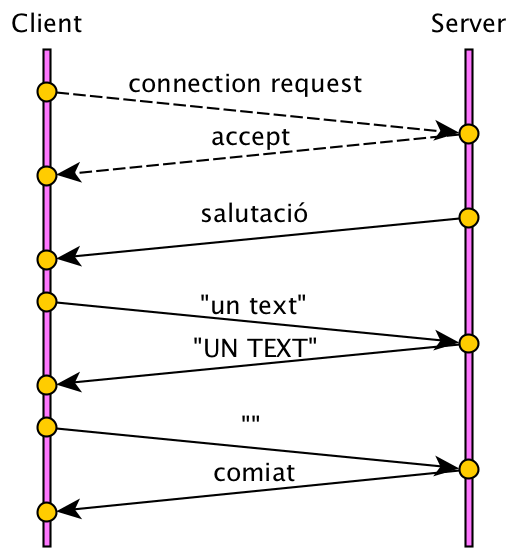
This could be server code that implements the described protocol using TCP.
ServerSocket serverSocket = new ServerSocket(PORT);
Socket clientSocket = serverSocket.accept();
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
out.println("hola!");
String text;
while ((text = in.readLine()).length() > 0)
out.println(text.toUpperCase());
out.println("adeu!");
clientSocket.close();
serverSocket.close();
You can test this using the netcat (nc) command.
What would the protocol for this service be like? In pseudocode:
- When you connect to the server, send a line with a greeting.
- For each line you send, it returns the same line in capital letters.
- When you send a blank line, it replies with goodbye, and disconnects.
Next, you can see a client accessing this service, implementing this protocol.
Socket clientSocket = new Socket(HOST, PORT);
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
String salutacio = in.readLine();
System.out.println("salutacio: " + salutacio);
for (String text: new String[]{"u", "dos", "tres"}) {
out.println(text);
String resposta = in.readLine();
System.out.println(text + " => " + resposta);
}
out.println();
String comiat = in.readLine();
System.out.println("comiat: " + comiat);
in.close();
out.close();
clientSocket.close();
Text-based communication
In the examples we've seen, PrintWriter and BufferedReader are the objects that allow text strings to be used on the OutputStream and InputStream respectively, which are binary media.
The most correct thing in these cases would be to indicate which is the Charset with which we encode the Strings. If we wanted to use UTF-8, it would look like this:
Charset UTF8 = StandardCharsets.UTF_8;
PrintWriter out = new PrintWriter(new OutputStreamWriter(socket.getOutputStream(), UTF8), true);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream(), UTF8));
Related to charset, we have conversion to and from String from binary data, which we can perform in UDP. These are the two operations:
byte[] strBytes = "Hola, món!".getBytes(UTF8);
String str = new String(strBytes, UTF8);
UDP communication
With UDP there is no connection: packets (Datagrams) are simply sent to a UDP server. If we want to reply, we need to know the destination address and port, which can be obtained from the received package.
A server can be created with:
DatagramSocket socket = new DatagramSocket(PORT)
The client works exactly the same, but the socket is created with:
DatagramSocket socket = new DatagramSocket();
To receive a maximum size package (MIDA):
byte[] buf = new byte[MIDA];
DatagramPacket paquet = new DatagramPacket(buf, MIDA);
socket.receive(paquet);
// data in packet.getData() and source in packet.getAddress() and packet.getPort()
To send a packet to the server:
InetAddress address = InetAddress.getByName(HOST);
paquet = new DatagramPacket(buf, MIDA, address, PORT);
socket.send(paquet);
To send a response packet to a client, we need to use the port in the packet it previously sent us:
InetAddress address = paquetRebut.getAddress();
int port = paquetRebut.getPort();
DatagramPacket paquetResposta = new DatagramPacket(buf, buf.length, address, port);
socket.send(paquet);
Competition
How can we make servers accept concurrent requests from multiple clients?
We saw it in the UF "Processes and Threads". Each request should be handled in a separate thread. For example, for the case of TCP:
Executor executor = Executors.newFixedThreadPool(NFILS);
ServerSocket serverSocket = new ServerSocket(PORT);
while (true) {
final Socket clientSocket = serverSocket.accept();
Runnable tasca = new Runnable() {
public void run() {
atendrePeticio(clientSocket);
}
};
executor.execute(tasca);
}
That way, we don't keep new customers waiting when we serve one.
Timers
When we use TCP sockets, connection and data sending operations require confirmation from the other party. By default, the API we've seen has no timers (timeouts), and blocks indefinitely.
There is also the UDP operation of reading a datagram, which by default blocks waiting for a response.
Here are the TCP connection operations:
new Socket(host, port...): creation of a socket and connection without timeout.new Socket(): Create an unconnected socket (no blocking).Socket.connect(SocketAddress, timeout): Connect an unconnected socket with a timeout.
Once a TCP socket is created, either client (Socket) or server (ServerSocket), we can change the timeout using Socket.setSoTimeout(int timeout). When the timer expires, an exception of type SocketTimeoutException is thrown. This timeout (in milliseconds) affects the following TCP/UDP operations:
ServerSocket.accept(): Accepting a connection from a client to the TCP server.SocketInputStream.read(): Read data to a TCP socket.DatagramSocket.receive(): Reading a UDP datagram.
Closing
Here are some aspects associated with closing a TCP socket:
- We can check if a TCP connection is closed with
Socket.isClosed()andServerSocket.isClosed(). - If we close a socket connection with
Socket.close(), itsInputStreamandOutputStreamstreams are automatically closed. - If we close the connection of any of its streams, that of the associated socket is automatically closed.
- If we do a
ServerSocket.close()and it is waiting with aServerSocket.accept(), it will abort and throw a SocketException. - If one socket is waiting with a
SocketInputStream.read()and the other socket closes, theread()operation will be aborted and a SocketException will be thrown. - If one socket is waiting in a text channel with a
BufferedReader.read()orBufferedReader.readLine()and the other socket closes, a -1 or null will be returned, respectively.
Asynchronous communication
Based on the NIO libraries. See this post.
Services
Architectures
An application can be seen as four components: data, data access logic, application logic, and presentation. These components can be distributed in many ways:
- server-based: The server does pretty much all the work. Customers are very light.
- client-based: The client does pretty much all the work. The server only saves the data.
- peer-to-peer: machines act as client and server and share the work, which they do comprehensively.
- client/server: The dominant architecture. The application and data access logic can be distributed between client and server. They can have multiple layers: 2, 3, N. Allows applications from different providers to be integrated using standard protocols. This is the dominant architecture.
Client/server architecture is usually data-centric: business logic is sandwiched between that data and the user interface, usually web. An example pattern is the MVC (model/view/controller).
If we look at the criterion of where the HTML of a web application is generated we can have:
- The traditional: HTML is generated on the server.
- The SPA (Single-Page Application): HTML is generated on the client, and data (JSON, usually) is exchanged with the server. On the server we implement APIs based on HTTP, which can be shared with different types of clients such as browsers or mobile applications.
When functionalities grow and are added to a solution, we run the risk of turning our application into what is called a monolithic application. Some architectural solutions propose solutions:
- Microservice Architecture: It proposes completely independent services that provide self-contained functionality. All of them communicate with lightweight protocols (they can be heterogeneous) based on REST/HTTP thanks to a well-established contract (API). Based on the idea of the event loop.
- Service Oriented Architecture (SOA): A similar solution to the above, but services communicate using a more complex middleware called enterprise service bus (ESB). Based on the coordination of multiple bus services.
APIs
The world is increasingly interconnected through APIs that provide services. These can be public, in order to add value to a company's business.
APIs are said to be managed when they have a well-defined life cycle:
CREATED ➡ PUBLISHED ➡ OBSOLETE ➡ WITHDRAWN
They are only published once they are well documented, with their quality of use rules, such as usage limitation. The standard and open way to describe APIs is through OpenAPI.
Example: Twitter API
HTTP
The HTTP protocol is implemented on top of TCP, usually on port 80. This allows us to implement an HTTP server using sockets.
To write the server, we need to be able to read an HTTP request and respond.
Request
request = Request-Line
*(<message-header>)
CRLF
[<message-body>]
The Request-Line has the format:
Request-Line = Method URI HTTP-Version
The most common methods are GET/POST. The version, HTTP/1.1. The URI is just the absolute path part.
The most common headers are:
- Host (required): Specifies the domain name of the server.
- Accept: informs the server about the types of data that can be received.
The message-body is empty for the GET method, and contains the form fields for the POST method.
When it is POST, the Content-Type header is sent with the values:
- application/x-www-form-urlencoded: values encoded in key-value tuples separated by &, with an = between key and value. Non-alphanumeric values must be encoded in percent code. In Java it can be done with
URLEncoder.encode(query, "UTF-8"). - multipart/form-data: transmission of binary data, eg a file.
- text/plain: text format.
Response
response = Status-Line
*(<message-header>)
CRLF
[<message-body>]
The Status-Line has the format:
HTTP-Version Status-Code Reason-Phrase
We have already seen the status codes. The Reason-Phrase is readable text that explains the code.
The most common headers are:
- Content-Type: The MIME type (media) returned. May include the charset. Example:
text/html; charset=UTF-8. - Content-Length: The number of bytes of content returned.
- Date: The date of the returned content.
- Server: The name of the server.
The message-body has the content of the fetched resource.
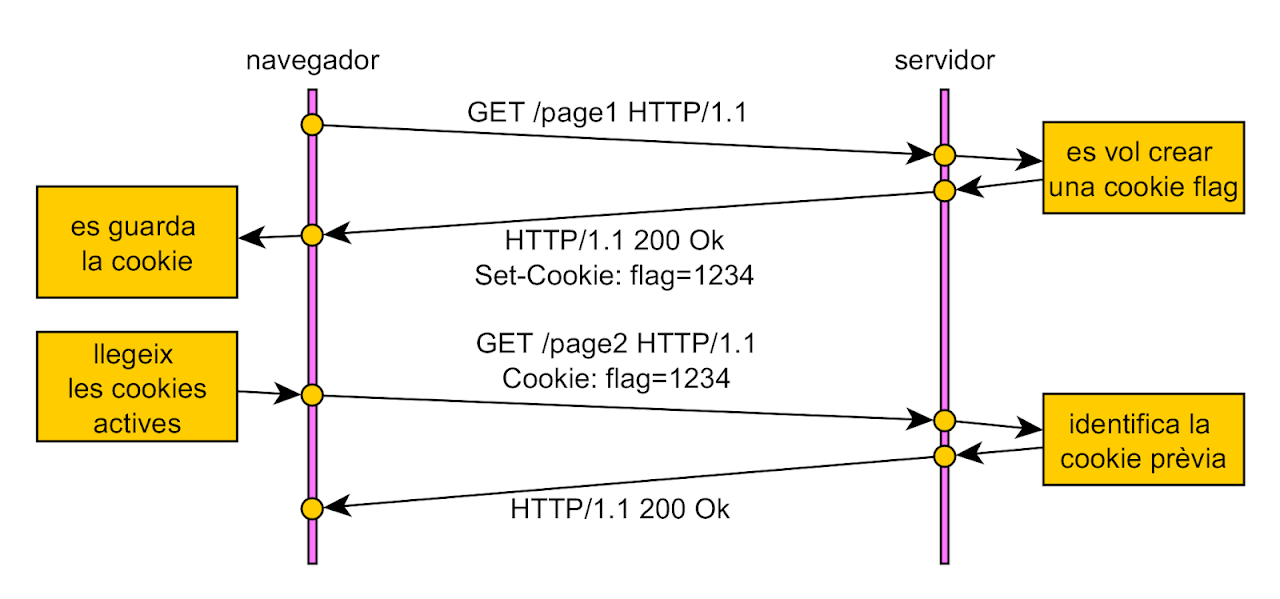
Cookies
Cookies are a mechanism that allows key/value pairs to be stored in the browser from an HTTP server. It can be used for different purposes, for example to identify a user session, or to select a display preference, such as language.
There are two headers associated with this mechanism:
- Set-Cookie: header that is written from the server's response to assign a cookie.
- Cookie: header that is read from the browser request with the values of the cookies stored there.
To delete a cookie, just send the empty cookie with a date in the old "expires" field:
- Set-Cookie: nomgaleta=; expires=Thu, 01-Jan-1970 00:00:00 GMT;
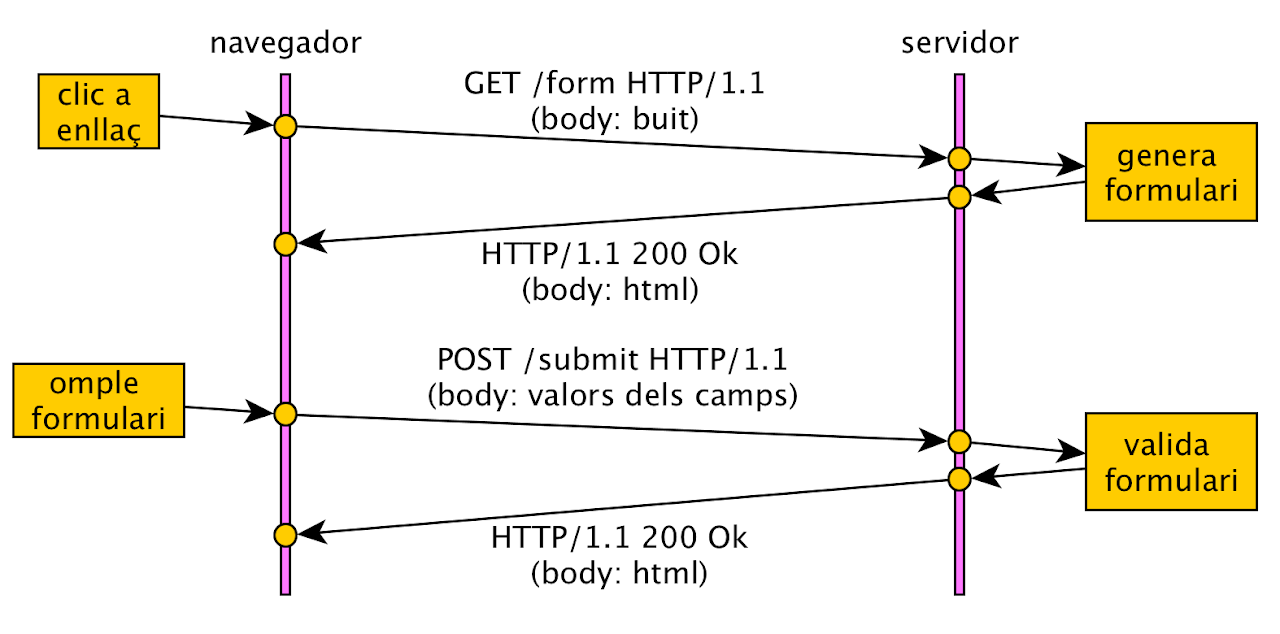
Example GET/POST from an HTML form: The /form URI displays a form, which is filled out and processed by the /submit URI.
Cookie example: The /page1 URI stores a cookie, which is then available to other pages.
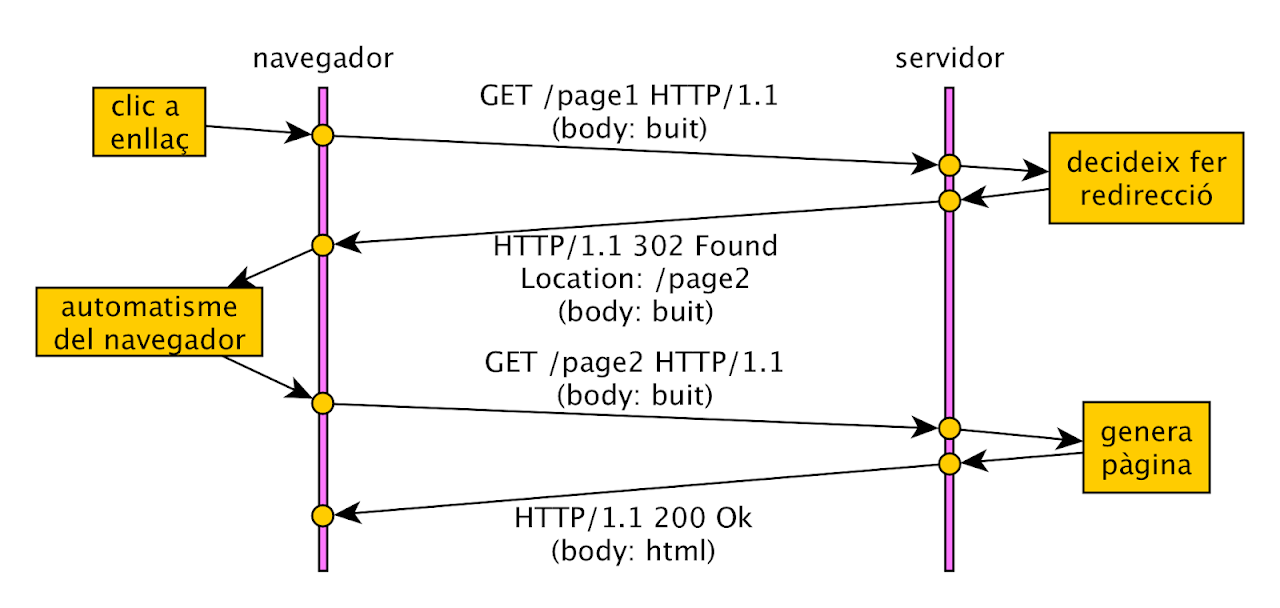
Redirection Example: The URI /page1 is redirected to /page2.
HTTP APIs
We will see two types of protocols over HTTP: one stateless and another stateful.
RESTful API
REST (Representational State Transfer) is an architectural style for distributed systems. Allows applications to communicate with services provided on the web. In order for an interface to be called RESTful, it must meet a number of principles:
- Must implement a client/server scheme. This allows them to be developed independently, and to replace them.
- It must be stateless (without state on the server). Therefore, the state must be persisted on the client. This improves the scalability, availability and performance of the application.
- Information must be given to the client (implicitly or explicitly) whether the content is cacheable. Thus, scalability and performance can be improved.
- It must have a uniform interface. Basically, a resource must be associated with a URI that allows access to its data.
- It must be designed as a layered system. The client cannot know specifically the architecture of the service or where the data resides, for example.
- Optionally, the client can request code from the server, to simplify its implementation (unusual).
Although not required, a RESTful service often uses HTTP as its protocol. In this case, the bodies of requests and responses are usually in XML or JSON format.
If we look at common CRUD operations, there is a convention of how to use HTTP methods using status codes 200, 201, 204, 400, 404 :
- GET: read (idempotent).
- POST: create (not cacheable).
- PUT: update/replace.
- DELETE: delete.
- PATCH: partial modification.
Since the protocol is stateless, authentication/authorization must occur for each request. Best practices include using secure channels, and never exposing data in the URL. The use of Oauth is also recommended.
The use of tokens, or passwords, is common in authentication systems. The operation with token is as follows:
- The user or client application accesses the authentication service.
- If it is correct, the server generates a token that it sends to the client.
- The user accesses the resources with their token.
Streaming API
A streaming protocol is precisely an inversion of RESTful. This is not a conversation. It's about opening a connection between a client and the API, where the client receives the nine results as they occur, in real time.
It is stateful in nature, as the API sends the results based on the customer's profile and/or the filtering rules you have set.
It is common to use the JSON format. In this case, the text format is used and messages can be delimited with line breaks.
An example is that of Twitter.
Criptography
Learning results (shared with Security):
- Protect applications and data by defining and applying security criteria in the access, storage and transmission of information.
References
- Java Security Standard Algorithm Names, JDK 11
- Cryptographic Storage Cheat Sheet
- Security Developer’s Guide, JDK 11 Providers Documentation
- Block cipher mode of operation
- Java Criptography (Jenkov)
- Cryptographic hash function (Wikipedia)
- Public-key cryptography (Wikipedia)
- Java Security 2nd Edition (examples)
- Practical Cryptography for Developers
- Establishing a TLS Connection
- Generating and Verifying Signatures (The Java Tutorials)
- A Deep Dive on End-to-End Encryption: How Do Public Key Encryption Systems Work?
- Java Keytool - Commands and Tutorials
- Java KeyStores - the gory details
- Trusted Timestamping (Wikipedia)
- CyberChef
- Capture The Flag 101
- SideKEK
Concepts
- Authentication
- Encryption
- States of the data
- Encryption type
- Key exchange
- Message digests
- Digital signatures
- Certificates
Kerckhoffs principle: "The effectiveness of the system must not depend on its design remaining secret.".
Authentication
Authentication is the process of confirming the authenticity claimed by an entity. We basically have two types:
- author authentication: the author is who they say they are. It can be achieved with a digital signature.
- data authentication: the data has not been modified. It can be achieved with a message digest algorithm.
Authentication does not mean we have encryption.
Encryption
Cryptography (from the Greek "kryptos" - hidden, secret - and "graphin" - writing. Therefore it would be "hidden writing") is the study of ways to convert information from its form original to an incomprehensible code, so that it is incomprehensible to those who do not know this technique.
In cryptography terminology, we find the following elements:
- The original information that must be protected and that is called plaintext.
- Encryption is the process of converting plaintext into unreadable text, called ciphertext or cryptogram.
- Keys are the basis of cryptography, and are strings of numbers with mathematical properties.
States of the data
In a secure system, when data is to be used (in use) it must be plaintext. But if it is stored or transmitted, it must be kept secret. These are the states:
- At Rest: when stored digitally on a device.
- In transit: when they are moving between devices or network points.
- In Use: When an application is in use, unprotected.
When we protect data at rest, we prepare our system for the eventuality that it can be read after an attack on the machine it is on. When we protect data in transit, we do so because we know that anyone can listen to network traffic.
If our encrypted data is exposed, and they gain access to the associated secret keys (either now or later), they will be able to see it in plain sight.
Sometimes we can avoid having to save them. For example, if we can ask for them every time (eg master key), or compare them with digests (eg passwords).
Encryption type
There are two large groups of encryption algorithms, depending on whether the keys are unique or in pairs:
- Symmetric: algorithms that use a single private key to encrypt information and the same private key to decrypt it.
- Asymmetric: those that have two keys, one public and one private, which allows encryption with either one and decryption with the other. They are mainly used for two purposes:
- Public key encryption: A message encrypted with a public key can only be decrypted with the private key.
- Digital signature: A message signed with the private key can be verified by anyone with the public key.
The symmetric key has drawbacks. First, you need a key for each source/destination pair. Second, you need a secure way to share them. The asymmetric key has the advantage that you can share the public part of the key, since without the private part you can't do anything, but the algorithms are slower and have limitations on the size of the message to be encrypted. For example, RSA has a maximum message of `floor(n/8)-11 bytes'.
Encryption can also be block or stream:
- Block: Encryption of fixed size blocks of data. They can be asymmetrical or symmetrical.
- Stream: encryption of a stream (current) of bits or bytes. They are symmetrical.
Unless otherwise stated, we are only talking about block ciphers.
Symmetric encryption: Both parties share a private key
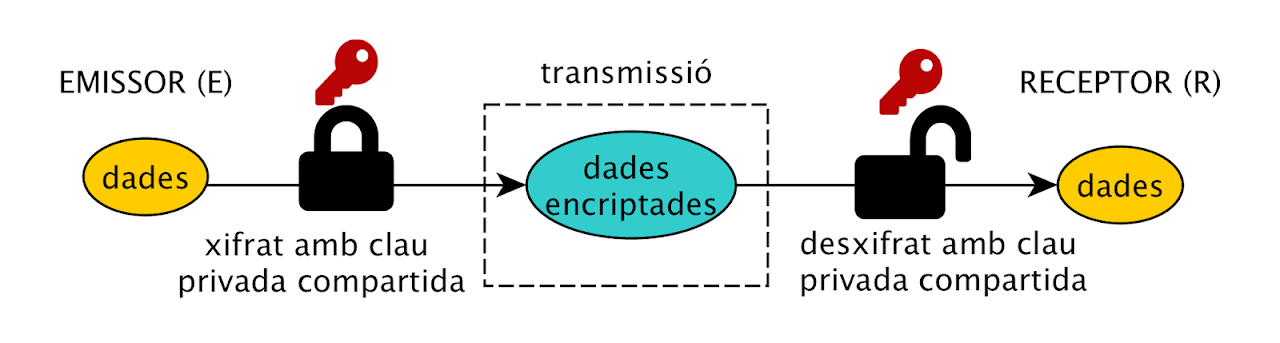
Asymmetric encryption: Only the owner of the keys (the receiver) can decrypt the data
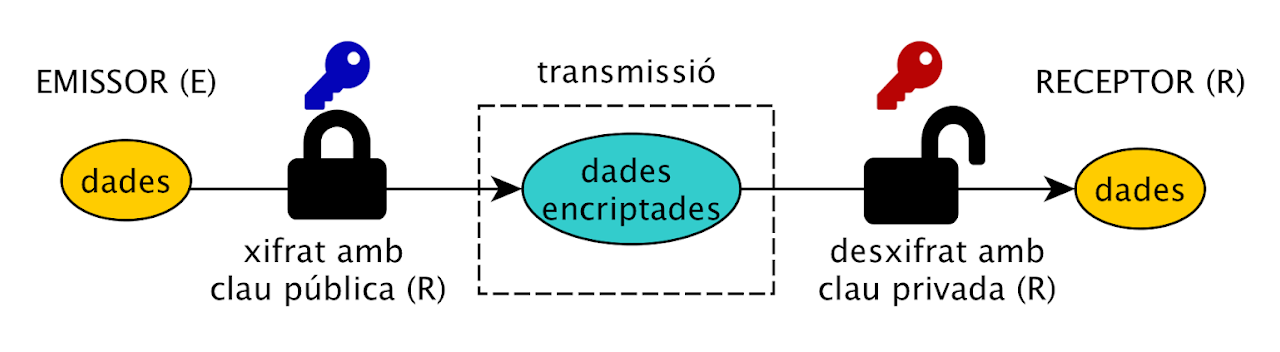
Key exchange
As we have already seen, symmetric encryption has the problem of sharing the key between the two parties. And asymmetric, it does not allow to encrypt very large blocks.
The solution is to use both types of encryption in combination.
- Asymmetric cryptography allows us to share a private key securely.
- Symmetric cryptography allows us to encrypt longer and faster messages.
The simplest key exchange can be done with RSA public key encryption: one party encrypts the shared secret with the other's public key. The problem is that this action is not "forward secret": if someone gets the private key in the future, and has saved the secret conversation, they could decrypt it.
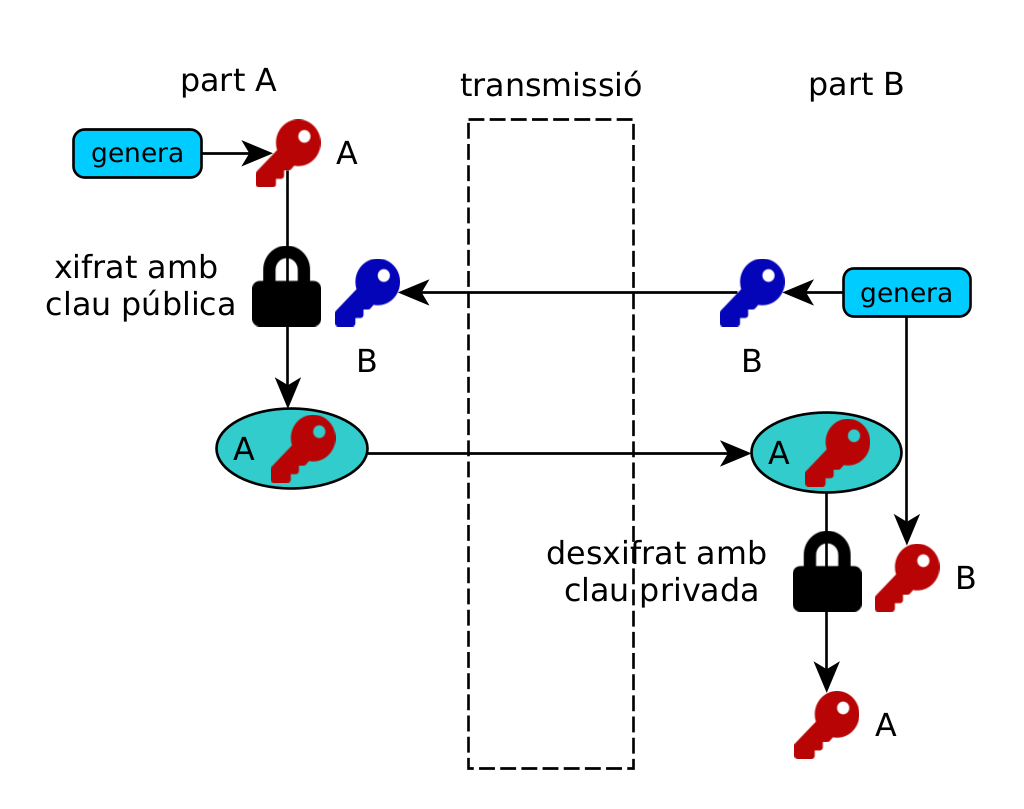
However, the most common algorithm for key exchange is Diffie-Hellman (DH), present in the preamble of most communications with symmetric encryption.
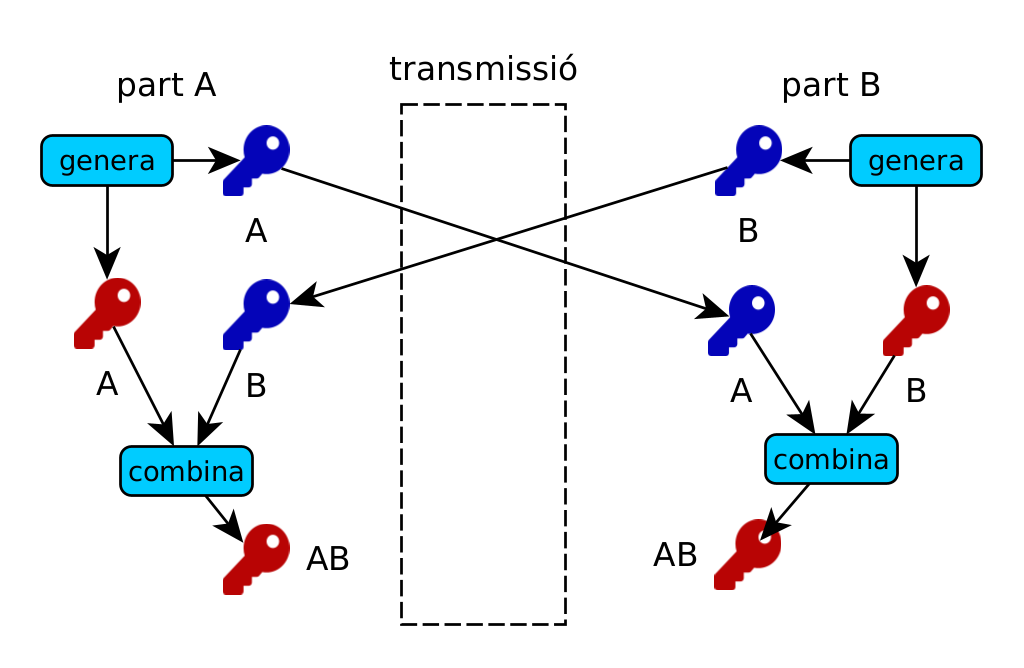
For two parts A and B, the process is as follows:
- A and B generate two public/private key pairs, Apub/Apri and Bpub/Bpri.
- The two parties exchange the public keys Apub and Bpub.
- In private, each party combines the public keys received with the private ones (Apub+Bpri, Bpub+Apri). The essential feature of DH is that this combination generates the same secret!
Message digests
A "message digest" or hash is a sequence of bytes produced when a set of data is passed through an engine. A key is not always required for this engine to operate. Some well-known ones: MD5, SHA-256. Its properties are:
- It is deterministic (same result for the same input).
- It is fast.
- The inverse function is not feasible.
- A small change in input causes a large change in output.
- Two different entries cannot have the same hash.
A digest allows us to protect the integrity of a message.
Let's see how SHA-256 works on Linux over a small "hello world!" text. If you try it, you will see that the result is instant (2). Since it is 256 bits, it generates a 32-byte digest (in hex). See how changing one character completely changes the hash (4).
$ echo 'hello world!' | openssl sha256
(stdin)= ecf701f727d9e2d77c4aa49ac6fbbcc997278aca010bddeeb961c10cf54d435a
$ echo 'hello,world!' | openssl sha256
(stdin)= 4c4b3456b6fb52e6422fc2d1b4b35da2afbb4f44d737bb5fc98be6db7962073f
If you are looking for the summary of "hello world!" or "123456" you will find it on the net. Two conclusions: for one algorithm and one input, we have the same output (1). We don't have the reverse function (3), but there are summary tables for matching texts, which are used to figure out credentials.
If we want to protect integrity and authenticity, we can use MAC (message authentication code). Basically, these are secure digests encrypted with a private key that needs to be shared between the two parties in order to verify the communication.
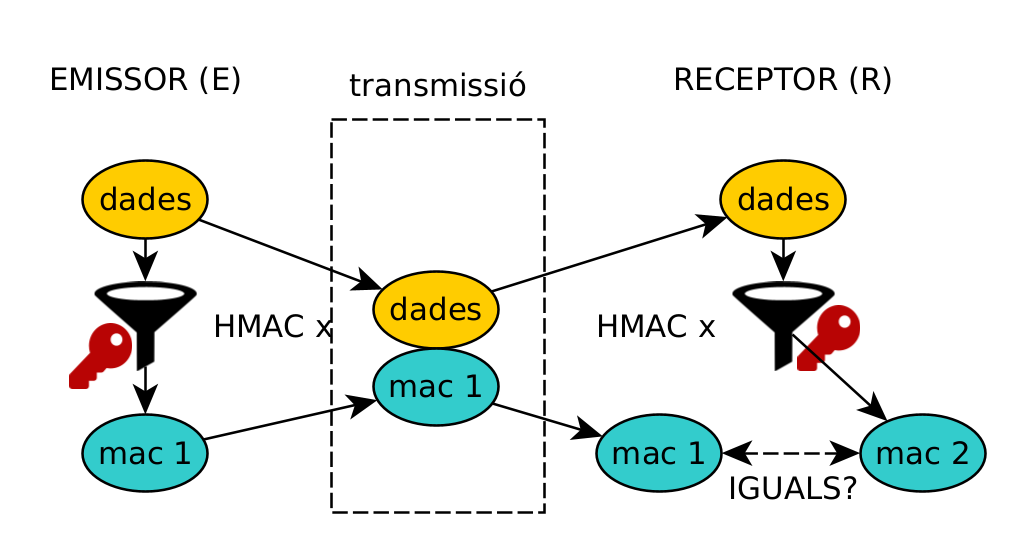
We also have the Key Derivation Functions (KDF), a hash that allows one or more secrets to be derived from another smaller one, such as a password. KDFs allow extending keys (key stretching) into longer ones.
In the following diagram you can see two uses of KDFs:
- To save a hash of a password, and to be able to check if it is entered correctly.
- To generate symmetric algorithm keys from a password.
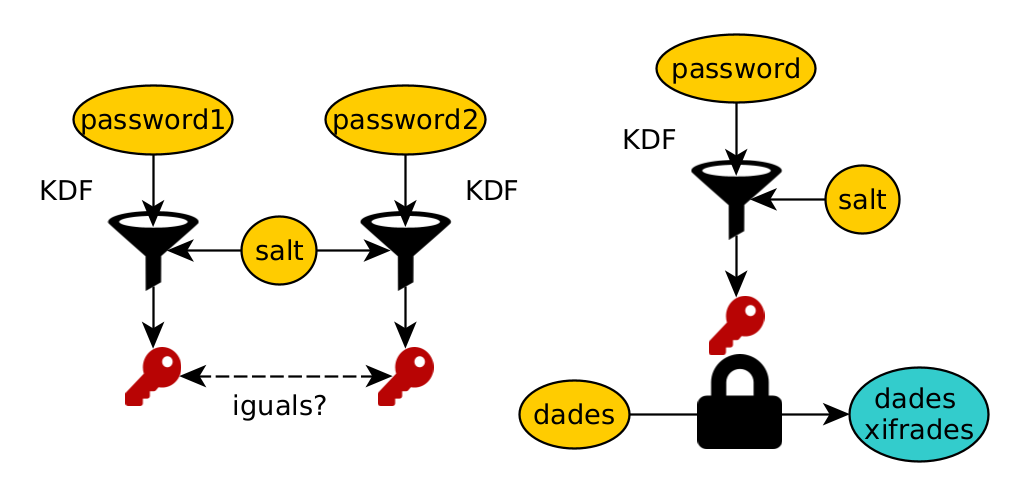
Digital signatures
The digital signature is an encryption mechanism to authenticate digital information. The mechanism used is public key cryptography. That is why this type of signature is also called a public key digital signature. They are used to guarantee three aspects: authenticity, integrity and non-repudiation.
This is the process to obtain a digital signature:
- A message digest is calculated for the input data.
- The summary is encrypted with the private key.
This is the process to verify a digital signature:
- A message digest is calculated for the input data.
- The summary of the digital signature is decrypted with the public key.
- The two summaries are compared. If they are the same, the signature is correct.
Digital Signature: The owner of the keys (the issuer) sends proof of the original data
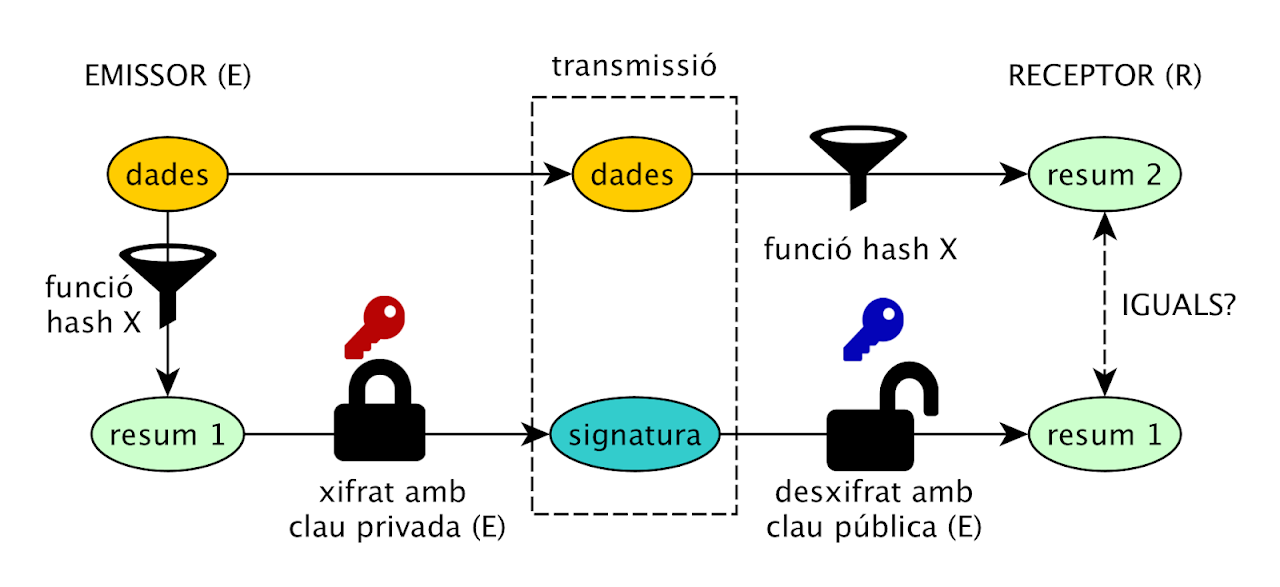
Certificates
If a digital document is signed using a private key, the recipient must have the public key to verify the signature. The problem is that a key does not indicate who it belongs to. Certificates solve this problem: a well-known entity (Certificate Authority: CA) verifies ownership of the public key sent to you.
A certificate contains:
- The name of the entity by which the certificate was issued.
- The public key of this entity.
- The digital signature that verifies the information in the certificate, made with the issuer's private key.
A certificate could contain this information:
"Certificate authority 2276172 certifies that John Doe's public key is 217126371812."
Problem: The certificate issuer has a public key that we need to trust. And they can be chained. The last of the chain is self-signed by herself. Then we need to accept certain CAs as trusted, and usually Java (as well as browsers) have a list of trusted CAs.
The TLS/SSL server certificate is the most common. The client uses the Certification Path Validation Algorithm:
- The subject (CN) of the certificate matches the domain it connects to.
- The certificate is signed by a trusted CA.
How do you establish secure communication between your browser and an HTTPS server?
- When the browser connects to the server it downloads its certificate, which contains its public key.
- The browser has the public keys of the trusted CAs, and checks if the certificate has been signed by a trusted CA.
- The browser checks that the domain that appears in the certificate is the same with which it communicates with the server.
- The browser generates a symmetric key, encrypts it with the server's public key and sends it.
- Asymmetric encryption ends and symmetric encryption with the shared key begins.
Cryptography in Java
Java cryptographic engines provide mechanisms for digital signatures, message digests, etc. These engines are implemented by security providers (java.security.Provider), which can be viewed using java.security.Security.getProviders(). Each engine (java.security.Provider.Service) has a type and an algorithm.
Keys
We can generate keys of symmetric type (KeyGenerator) or asymmetric type (KeyPairGenerator).
KeyGenerator keyGen = KeyGenerator.getInstance(algorithm);
keyGen.init(size);
SecretKey secretKey = keyGen.generateKey();
Typical symmetric algorithms are DES (56-bit) or AES (128, 192, 256 bits).
KeyPairGenerator kpg = KeyPairGenerator.getInstance(algorithm);
kpg.initialize(size);
KeyPair kp = kpg.generateKeyPair();
PublicKey publicKey = kp.getPublic();
PrivateKey privateKey = kp.getPrivate();
The algorithm must be indicated. The most common is RSA (1024, 2048 bits).
Both SecretKey, PublicKey and PrivateKey are subclasses of java.security.Key. All of them have a getEncoded() method: the key in binary format.
Encryption
To be able to encrypt, we need an object javax.crypto.Cipher:
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
The format of the parameter (transformation) is algorithm/mode/padding. Mode and padding are optional: if not specified, the default mode and padding are used. Which are?
- Padding: is a technique that consists of adding padding data to the beginning, middle or end of a message before being encrypted. This is done because the algorithms are designed to have input data of a particular size.
- Mode: Defines how the input (plain) and output (encrypted) blocks are mapped. The simplest is the ECB mode: an input block goes to an output block. Other, more secure modes randomize this correspondence.
Then, we need to initialize the object using the mode (Cipher.ENCRYPT_MODE or Cipher.DECRYPT_MODE) and the encryption key:
cipher.init(Cipher.ENCRYPT_MODE, key); // encryption
cipher.init(Cipher.DECRYPT_MODE, key); // decryption
Finally, we perform the encryption or decryption:
byte[] bytesOriginal = textOriginal.getBytes("UTF-8"); // I need bytes as input
byte[] bytesEncrypted = cipher.doFinal(bytesOriginal);
The decryption could be:
byte[] bytesDeciphered = cipher.doFinal(bytesDeciphered);
// alternatively, if the content to be decrypted is part of the array:
byte[] bytesDeciphered = cipher.doFinal(bytesDeciphered, start, length);
Some block cipher modes use what is called an initialization vector (IV). This is a random parameter for the encryption algorithm that makes it harder to match blocks based on their inputs. It usually doesn't need to be secret, just not repeated with the same key.
To use these modes (eg CBC), a new parameter must be added when the Cipher is initialized. The size of the IV is usually the same as the block. For AES it is 16 bytes (256 bits).
byte[] iv;
// initialize IV with a random generator like SecureRandom
IvParameterSpec parameterSpec = new IvParameterSpec(iv);
cipher.init(Cipher.ENCRYPT_MODE, key, parameterSpec); // encryption
cipher.init(Cipher.DECRYPT_MODE, key, parameterSpec); // decryption
Encryption of streams
It makes no sense to encrypt large amounts of data with block methods. For these situations, we can use stream encryption. This cipher is always symmetric.
In Java, we have the classes CipherInputStream and CipherOutputStream.
CipherInputStream and CipherOutputStream support a block symmetric Cipher, such as AES/ECB/PKCS5Padding, or feedback type modes CFB8 or OFB8, (8 = 8-bit blocks), such as AES/CFB8/NoPadding. Feedback modes need initialization vectors (IV).
For example, if we want to open a file and encrypt or decrypt it, we can do it like this:
FileInputStream in = new FileInputStream(inputFilename);
FileOutputStream fileOut = new FileOutputStream(outputFilename);
CipherOutputStream out = new CipherOutputStream(fileOut, cipher);
Then, it would be necessary to copy the stream in to out.
The cipher object must be initialized with the required mode, ENCRYPT_MODE or DECRYPT_MODE.
CipherInputStream can be used analogously. In this case, the output stream could be a FileOutputStream:
FileInputStream fileIn = new FileInputStream(inputFilename);
CipherInputStream in = new CipherInputStream(fileIn, cipher);
FileOutputStream fileOut = new FileOutputStream(outputFilename);
Binary data in text
The keys and encrypted information are in binary format. If it needs to be exchanged using a text channel, they can be converted using Base64. In Java, we have java.util.Base64.
byte[] binary1 = ...;
String string = Base64.getEncoder().encodeToString(binary1);
byte[] binary2 = Base64.getDecoder().decode(string);
// binary1 and binary2 are equal
Hashes, signatures and certificates
Message summaries
Digests are implemented using the java.security.MessageDigest class, which allows you to generate a data digest. The digest can be made secure using javax.crypto.Mac. The operation can also be performed with Streams thanks to java.security.DigestInputStream and java.security.DigestOutputStream.
Some typical digest algorithms: MD2, MD5, SHA-1, SHA-256, SHA-384, SHA-512.
MessageDigest messageDigest = MessageDigest.getInstance(algorithm);
byte[] digest = messageDigest.digest(text.getBytes(StandardCharsets.UTF_8));
Secure digests
A Message Authentication Code (javax.crypto.Mac) is a digest encrypted with a shared private key. It can only be verified if you have this key. We can generate it like this:
Mac mac = Mac.getInstance(algorithm);
mac.init(key); // the private key
byte[] macBytes = mac.doFinal(text.getBytes(StandardCharsets.UTF_8));
An algorithm could be HmacSHA256 (HMAC: Hash-based MAC).
Key Derivation Functions
With a KDF, we can generate a key longer than a password, for example. Here we have an example using the PBKDF2WithHmacSHA256 algorithm.
SecretKeyFactory f = SecretKeyFactory.getInstance("PBKDF2WithHmacSHA256");
KeySpec ks = new PBEKeySpec(password, salt, iterationCount, keyLength);
SecretKey rawSecret = f.generateSecret(ks); // generic secret
SecretKey aesSecret = new SecretKeySpec(s.getEncoded(), "AES"); // AES secret
The KeySpec parameters are:
- password: a char[] with the password.
- salt: A salt to randomize the hash.
- iterationCount: number of iterations to generate the hash.
- keyLength: length of the key to generate.
Digital signatures
A digital signature is equivalent to making a summary and encrypting it with a private key. The receiver could decipher it with the public, and compare it with a summary of the data (plan) received.
Algorithms are varied, for example SHA256withRSA indicates that hashing is done with SHA256 and encryption with RSA. Therefore, the keys used must be RSA. To sign an input (byte array):
Signature sign = Signature.getInstance(algorithm);
sign.initSign(privateKey);
sign.update(input);
byte[] signature = sign.sign();
To verify it:
Signature sign = Signature.getInstance(algorithm);
sign.initVerify(publicKey);
sign.update(input);
boolean correct = sign.verify(signature);
Certificates
The most common certificates (java.security.cert.Certificate) are of type X.509, and indicate a binding of an identity to a public key, guaranteed by another authorized entity. They include:
- start and end date
- version (currently 3)
- serial number (unique per supplier)
- the DN (distinguished name) of the issuing CA
- the DN of the subject of the certificate
DNs (Distinguished Names) contain a series of fields (CN, OU, O, L, S, C) that identify both the issuer and the subject.
Usually, we find them inside warehouses. To manage them we can use the JRE keytool tool or programmatically with the java.security.KeyStore class and the getKey(alias) (private key) and getCertificate(alias) (certificate where there is the public key).
They are required on web portals with HTTPS security enabled.
SSL communication with sockets
In order for a socket to communicate with the secure SSL protocol, you need to create slightly different objects.
On the server:
ServerSocket serverSocket = new ServerSocket(PORT);
They become:
SSLServerSocketFactory factory = (SSLServerSocketFactory) SSLServerSocketFactory.getDefault();
SSLServerSocket serverSocket = (SSLServerSocket) factory.createServerSocket(PORT);
Optionally, if we want to authenticate the client (we will see this later):
serverSocket.setNeedClientAuth(true);
To the client:
Socket clientSocket = new Socket(HOST, PORT);
They become:
SSLSocketFactory factory = (SSLSocketFactory) SSLSocketFactory.getDefault();
SSLSocket clientSocket = (SSLSocket) factory.createSocket(HOST, PORT);
Also, you need to set up your private and public keys correctly. And this depends on whether or not we want to authorize the clients public key on the server.
We have two types of necessary warehouses:
- Keystores serve to identify us
- Truststores are used to authorize other parties
Configuration is done through system properties in Java, with this statement:
System.setProperty("nameOfTheProperty", "value");
No client authorization
You need to generate two warehouses:
- serverKeystore.jks - server public/private key
- clientTruststore.jks - server public key
keytool -genkey -alias srvAlias -keyalg RSA -keystore serverKeystore.jks -keysize 2048
keytool -export -keystore serverKeystore.jks -alias srvAlias -file server.crt
keytool -importcert -file server.crt -keystore clientTruststore.jks -alias srvAlias
Configuration on the server to identify yourself:
javax.net.ssl.keyStore=serverKeystore.jks
javax.net.ssl.keyStorePassword=yourpassword
Configuration on the client to accept on the server (only if the server is not authorized by a CA Authority):
javax.net.ssl.trustStore=clientTruststore.jks
javax.net.ssl.trustStorePassword=yourpassword
With client authorization
To the above configurations, you need to add:
- clientKeystore.jks: client public/private key
- serverTruststore.jks: Client public key
keytool -genkey -keyalg RSA -alias cltAlias -keystore clientKeystore.jks -keysize 2048
keytool -export -keystore clientKeystore.jks -alias cltAlias -file client.crt
keytool -importcert -file client.crt -keystore serverTruststore.jks -alias cltAlias
Configuration on the server to accept the client:
javax.net.ssl.trustStore=serverTruststore.jks
javax.net.ssl.trustStorePassword=yourpassword
Configuration on the client to identify itself:
javax.net.ssl.keyStore=clientKeystore.jks
javax.net.ssl.keyStorePassword=yourpassword
Key management
Generation and destruction
Generation tips:
- For symmetric encryption, use AES with at least 128 bits, preferably 256.
- Use authenticated modes if possible: GCM, CCM. If not, CTR or CBC. ECB should be avoided.
- For asymmetric encryption, use elliptic curve cryptography (ECC) like Curve25519. If not, use RSA of at least 2048 bits.
- Use safe random generators. Better CSPRNG than PRNG. In Java, always prefer SecureRandom over Random.
It is important to make the keys have a limited duration (rotate them): decrypt and re-encrypt. Key rotation is required if:
- If the previous key is known (or suspected) to have been compromised.
- When a certain predetermined time passes.
- When a certain amount of data has been encrypted.
- If the security associated with an algorithm has changed (new attacks).
Storage
Applications manage different types of secrets: credentials, encryption keys, certificate private keys, API keys, sensitive data, etc.
Secrets must be encrypted at rest and in transit. The keys to encrypt secrets are called Data Encryption Keys (DEK). These keys must also be protected, and what is done is to encrypt them using what is called Key Encryption Key (KEY) or "Master Key". This scheme makes it possible to modify the KEK while maintaining the DEK, and therefore, without requiring re-encryption of the data.
Key tips:
- If possible, never store the KEK. For example, ask for it interactively when needed.
- If feasible, use an HSM (Hardware Security Module).
- Better not to keep them in memory and plan.
- Never store them in code or git.
- DEKs and KEKs must be stored in separate locations. For example, the database and the file system, or on different machines.
- If they go to a file, protect the files with restrictive permissions.
- Do key stretching from a password to generate the KEK. For example, with the PBKDF2 key derivation function.
KeyStores
A keystore, or keystore, can have an alias, and can contain:
- Keys: Can be a key (asymmetric or symmetric). If it is asymmetric, it can contain a chain of certificates.
- Certificates: A public key, usually the root of trusted CAs.
Keystores can have different formats (JKS, JCEKS, PKCS12, PKCS11, DKS). The most used are:
- JKS (Java Key Store): Java's proprietary format. Historically, the most used. extension jks.
- PKCS#12: standard format. Recommended format. p12 or pfx extension.
Java has a tool called keytool for managing keystores. Below are some common orders.
Command to list the contents of a keystore:
$ keytool -list -v -keystore keystore.jks
Command to generate a keystore with a key pair:
$ keytool -genkey -alias mydomain -keyalg RSA -keystore keystore.jks -keysize 2048
Command to export a keystore certificate:
$ keytool -export -alias mydomain -file mydomain.crt -keystore keystore.jks
Command to import a certificate into a keystore:
$ keytool -importcert -file mydomain.crt -keystore keystore.jks -alias mydomain
Certificate formats
PEM - Privacy Enhanced Mail
PEM is the most common format in which Certificate Authorities issue certificates. These are mostly used by Unix/Linux users. They are encoded in base-64.
The public part of the certificate will be enclosed by "-----BEGIN PUBLIC KEY-----" and "-----END PUBLIC KEY-----", while the private part of the certificate is enclosed by "-----BEGIN RSA PRIVATE KEY––" and " -----END RSA PRIVATE KEY-----”.
The PEM format can contain any client/server certificate, intermediate certificate, root CA and private key.
- These are Base64 encoded ASCII files.
- They have extensions like .pem, .crt, .key (.cert sometimes).
- Apache and similar servers use PEM format certificates.
DER - Distinguished Encoding Rule
DER is a binary format certificate. All kinds of certificates and private keys can be encoded.
This format supports the storage of a single certificate and does not include the private key for the root/intermediate CA.
- These are files in binary format.
- They have extensions .cer and .der.
DER is typically used on the Java platform.
PKCS#7
This format only contains certificate or certificate chain, but does not store the private key.
CAs are commonly used to provide certificate chains to users, and they usually have a .p7b or .p7s extension.
PFX - Personal Information Exchange
PFX is a format for storing a server certificate or any intermediate certificate along with the private key in an encrypted file. PFX follows the Public Key Encryption Standard (PKCS). The term PFX is used interchangeably with PKCS#12.
They have a .pfx or .p12 extension.
Security
Learning results (shared with Criptography):
- Protect applications and data by defining and applying security criteria in the access, storage and transmission of information.
We will talk about logical security (software) and active security (preventive) associated with software development.
A system can be considered secure if we take care of the following aspects, from most to least significant:
- Availability: Users can access information when they need it.
- Confidentiality: Information is accessible only to those authorized to have access.
- Integrity: keep data free from unauthorized modification.
- Authentication: identity verification.
- Non-repudiation: Neither the sender nor the receiver can deny being a party to the communication that occurs.
Within the programming, and with reference to security, we will talk about the following aspects:
- Access control: registration, authentication and authorization of users.
- Secure design of software to avoid vulnerabilities.
References
Security:
- Security Features in Java SE (The Java Tutorials)
- Secure Coding Guidelines for Java SE
- Security by design (Wikipedia)
- Application Security (Wikipedia)
- SEI CERT Oracle Coding Standard for Java
- Top 10 Secure Coding Practices
- Secure Programming for Linux and Unix (Java specific)
- How to Learn Penetration Testing: A Beginners Tutorial
- OWASP Proactive Controls
- OWASP API Security Project
- Role-based access control (Wikipedia)
- Please, stop using local storage
- HTTP headers for the responsible developer
- How to Use Local Storage with JavaScript
- Application Architectures (Data Communications and Networking)
- Advanced API Security (Llibre)
- How secure is Java compared to other languages?
- The Rule Of 2
- Programming With Assertions
Authentication / authorization:
- HTTP Authentication
- Session vs Token Based Authentication
- The Web Authentication Guide Cheatsheet
- JWT, JWS and JWE for not so dummies!
- Java Authentication with JSON Web Tokens (jjwt)
- Tutorial: Create and Verify JWTs in Java
- Refresh Tokens: When to Use Them and How They Interact with JWTs
- Where to Store your JWTs – Cookies vs HTML5 Web Storage
- Attacking JWT authentication
- Token based authentication made easy
- Getting Token Authentication Right in a Stateless Single Page Application
- Stateless Sessions for Stateful Minds: JWTs Explained and How You Can Make The Switch
- Web Security for SPAs
- Webauthn guide
- An Introduction to OAuth 2
- OAuth 2.0 clients in Java programming, Part 1, Part 2 i Part 3
- LDAP Security
- REST Security Cheat Sheet (OWASP)
- Password Storage Cheat Sheet (OWASP)
- Cryptographic Storage Cheat Sheet (OWASP)
- REST API Security Essentials
Access control
Access control includes the activities of registration, authentication and authorization of users.
Registration
The user register is associated with the storage of that information necessary to be able to authenticate them later. It is important to avoid leaving information in the clear in files or databases, to save us security problems. Also, avoid encrypting passwords.
A common scheme is to use digests or hash. If we save the hash in the DBDD, we won't know what the password is, but we can compare what the user enters with the saved hash, and say if it's the same.
This has only one problem: there are pre-built tables to look up hash-to-password correspondences. This forces us to add a random string (jump) next to the password, and then the hash of everything is not always the same for the same password. This hop doesn't have to be private, it serves the purpose of making common password cracking tactics useless, and can therefore be kept in the clear in the DBDD.
When doing the authentication we will only have to make the comparison between the hash stored and the calculated one:
Is hash(salt + password1) equal to hash(salt + password2)?
Authentication
Authentication usually involves collecting the identification of the user in order to verify their authenticity.
Once we have the authenticated user, he can receive an identifier generated by the server and that the client will have to send each request to the server in order to confirm that he is authenticated.
The client / server applications can be differentiated into two types: stateful and stateless: with and without state. This refers to whether or not the server stores data associated with the authenticated user, which is called a session.
- Stateful: with session and data stored on the server. The identifier generated is that of the session. The server passes an ID to the client, which it uses every time it communicates with the server. The server uses it to get the data associated with it.
- Stateless: No session and data stored in the client. The generated identifier is called token. It can simply be a generated ID, or it can contain cryptographically signed information.
Identifier in the client
In web applications, if a client is authenticated it needs to let the server know using some sort of secret identifier. The client could be a browser, if it is a user web application, or a client application.
If the client is a browser, there are basically two schemes for saving this identifier on the client: cookies and web storage.
- cookies are part of the HTTP protocol. They allow name/value cookies to be saved via a "Set-Cookie" header from the server (response), and inform the server of current cookies via a "Cookie" header from the browser.
- The web storage is a mechanism that can be activated from the client exclusively, through scripting. We have two objects, sessionStorage and localStorage, that allow setItem/getItem type actions on name/value pairs. It is not a mechanism that directly replaces cookies, despite being similar.
Both of these technologies could store credentials to access applications. Cookies send the information directly to the server, while web storage allows the client to manage the information exclusively.
If it is a client application, this information can be saved by the corresponding software, and sent when needed to the server.
In the event that the identifier is not encrypted, it is important that it is not easily deduced to prevent malicious construction (random and long ID). JWT provides the option to encrypt access and authorization information.
Sending the identifier
Some possible methods for sending the identifier to the server are discussed below.
HTTP Basic Authentication uses a header of the type:
Authorization: Basic base64(username:password)
cookies are the most classic method, and allow two special headers, one from the server:
Set-Cookie: sessionId=shakiaNg0Leechiequaifuo6Hoochoh; path=/; Safe; HttpOnly; SameSite
and another from the client:
Cookie: sessionId=shakiaNg0Leechiequaifuo6Hoochoh
The tokens (bearer) are passed using a header:
Authorization: Bearer ujoomieHe2ZahC5b
Tokens usually have a validity limit, and are often used with stateless applications.
The signatures (signatures) sign and send the significant data of the request in form format. For example: AWS API.
TLS client certificates perform a handshake before any HTTP request.
Multi-factor authentication
Authentication can be based on something the user knows, has, or is. We can have a single authentication factor, or combine them. It is common to have two-factor authentication in more secure services.
A second common factor is the One-Time Password (OTP). They can be based on time synchronization or mathematical algorithms that generate strings. There are two implementations: HOTP (HMAC) and TOTP (Time). The difference is what they share to generate the password: a counter or time (Google Authenticator).
- The server creates a secret key for the user, and shares it with a QR code (it's long).
- Both parties will generate the OTP, and the server will have to validate if it is the expected one.
The generation is done with this formula:
- hash (shared secret + counter) = HOTP
- hash (shared secret + time) = TOTP
Authorization
Once the user has been authenticated, there are a number of permissions that are assigned to them based on their role within the application. There are different ways to assign them:
- Level: Users and tasks have levels, a user can do tasks with a level equal to or lower than their own.
- User: user-task pairs are made (many2many)
- Group: A user has a group, group-task pairs are made
- Responsibility: A user can have multiple groups
Once permissions are assigned, it is important to make them effective in each of the user's interactions with the system. This can be done both stateless (example: authorizations inside JWT) and stateful (storage in server session).
Authentication using session

Authentication using token

Secure design
- Design criteria
- Coding practices
- Practice in Java
- Analysis tools
- Top 10 controls
- Top 10 attacks on the web
Security should be a concern, not functionality.
Design criteria
Here is a list of possible criteria to consider for designing secure code:
- Least Privilege: An entity should only have the necessary set of permissions to perform the actions for which they are authorized, and no more.
- Default Fail-Safe: A user's default level of access to any system resource should be "denied" unless explicitly granted "permission".
- Mechanism Economy: The design should be as simple as possible. This makes them easier to inspect and trust.
- Complete Mediation: A system must validate access rights to each and every one of its resources.
- Open Design: Systems must be built openly, without secrets or confidential algorithms.
- Separation of privileges: Granting permissions to an entity must be based on multiple conditions, not just one.
- Less common mechanism: Anything that is shared between different components can be a communication path and a potential security hole, so the minimum possible data should be shared.
- Psychological acceptability: Security mechanisms should not make access to the resource more difficult than if they were not there.
- Responsibility: The system must record who is responsible for using a privilege. If there is abuse, we will be able to identify the person responsible.
Coding practices
Technical aspects that enhance the security of the code:
- Immutability: We can save ourselves problems associated with data integrity and availability.
- Fail-fast design by contracts: Clearly establishing what the preconditions and postconditions are for something to work correctly.
- Validation: We validate the origin, size, context, syntax and semantics of the data interacting with the system. There are libraries that help with this task, such as the Commons Validator.
Practice in Java
- Use access modifiers correctly and minimize coupling (minimum API).
- Avoid serialization, reflection and introspection.
- Do not expose credentials or personal information, or store it in source code or resource files: use the environment.
- Uses known and tested libraries, monitors third-party dependency vulnerabilities and updates to the latest version.
- Always use prepared statements (avoid SQL injection).
- Don't show implementation information in error messages.
- Checks that input to the system does not cause disproportionate use of CPU, memory and disk space.
- Always free resources: files, memory, etc.
- Check that primitive types such as integer do not overflow (you can use
addExact,multiplyExact,decrementExact).
Analysis tools
We have dynamic tools (which run the code) and static tools (which analyze the code without running it).
Dynamic:
- Integration and unit testing: You need to design integration and unit tests into the code. In Java, we have JUnit.
- Code coverage: tools used to detect which code has been executed or not, and decide if we need to add test cases. We have a coverage tool in Eclipse (Java), for example.
Static:
- Static code analysis: allows us to analyze the quality of the code we have written, with the detection of the most common semantic errors in the language. In Java, we can use SpotBugs and its two extensions, fb-contrib and find-sec-bugs.
Top 10 controls
According to OWASP 2018, this is the TOP 10 controls a developer should do:
- Define application security requirements. You need to identify, research, document, implement and test the functionalities in the application against the requirements. A good starting point can be the catalog at the ASVS.
- Take advantage of existing security libraries. Make a catalog of the bookstores, and make sure they are maintained and updated. Try to keep them always encapsulated, in case you need to replace them.
- Secure access to the database. This applies to queries (avoid injection), configuration (avoid default), authentication (user management), authorization (only necessary), and communication (encryption).
- Encode and escape the data. This allows any interpreter to not read special characters and allows unintended actions to be performed on the application. You can avoid injection and cross site scripting.
- Validate all entries. Always on the server, both syntactically (format: whitelisting / blacklisting) and semantically (value).
- Implement digital identity. We need to verify the user's identity (authentication), and perhaps maintain their state (session management). We can do this with passwords, with multi-factor and with cryptography.
- Force access control. Access must be allowed or denied granularly and for all requests. Criteria: deny by default, least privilege, avoiding hardcoded roles, and logging events.
- Protect data anywhere. Both in transit (end-to-end encryption) and at rest. At rest, if possible, do not store anything. On mobile, be more cautious and always use secure storage. In servers, never in code, better in environment variables.
- Implement security registration and monitoring. It allows us to use intrusion detection systems, perform forensic analysis and implement regulatory regulations.
- Handle all errors and exceptions. Make your code more secure and reliable. In addition, bugs can allow detection of attack attempts. Make a record, and if you show something to the user, that it doesn't contain critical data.
Top 10 attacks on the web
According to OWASP 2017:
- Injection: Injection faults, such as SQL, NoSQL, US or LDAP occur when untrusted data is sent to an interpreter, as part of a command or query. The attacker's malicious data can trick the interpreter into executing unintended commands or accessing data without proper authorization.
- Authentication Break: Application functions related to authentication and session management are implemented incorrectly, allowing attackers to compromise users and passwords, session tokens, or exploit other implementation flaws to assume identity of other users (temporarily or permanently).
- Exposure of sensitive data: Many web applications and APIs do not adequately protect sensitive data such as financial, health or Personally Identifiable Information (PII). Attackers can steal or improperly modify this protected data to commit credit card fraud, identity theft, or other crimes. Sensitive data requires additional protection methods, such as encryption in storage and in transit.
- External XML Entities (XXE): Many old or poorly configured XML processors evaluate references to external entities in XML documents. External entities can be used to reveal internal files via URI or internal files on out-of-date servers, scan LAN ports, execute code remotely, and perform denial-of-service (DoS) attacks.
- Loss of Access Control: Restrictions on what authenticated users can do are not properly enforced. Attackers can exploit these flaws to gain unauthorized access to functionality and/or data, other users' accounts, view sensitive files, modify data, change access rights and permissions, etc.
- Incorrect Security Configuration: Incorrect security configuration is a very common problem and is partly due to setting the configuration manually, ad hoc, or by default (or outright lack of configuration). Examples are: open S3 buckets, misconfigured HTTP headers, error messages with sensitive content, lack of patches and updates, outdated frameworks, dependencies and components, etc.
- Cross-Site Scripting (XSS): XSS occurs when an application takes untrusted data and sends it to the web browser without proper validation and encoding; or update an existing web page with user-supplied data using an API that executes JavaScript in the browser. They allow commands to be executed in the victim's browser and the attacker can hijack a session, modify websites, or redirect the user to a malicious site.
- Insecure Deserialization: These flaws occur when an application receives malicious serialized objects and these objects can be manipulated or deleted by the attacker to perform replay attacks, injections, or elevation of execution privileges. In the worst case, insecure deserialization can lead to remote code execution on the server.
- Using Vulnerable Components: Components such as libraries, frameworks, and other modules run with the same privileges as the application. If a vulnerable component is exploited, the attack can cause data loss or take control of the server. Applications and APIs that use components with known vulnerabilities can weaken application defenses and allow various attacks and impacts.
- Insufficient logging and monitoring: Insufficient logging and monitoring, along with a lack of response to incidents, allow attackers to sustain the attack over time, pivot to other systems, and manipulate, extract, or destroy data. Studies show that the detection time of a security breach is greater than 200 days, being typically detected by third parties rather than by internal processes.
Tecnologies
Webauthn
Webauthn (Web Authentication) is a web standard (W3C) specified by the FIDO Alliance that defines an interface to authenticate users to web applications and services using public key cryptography. In the client, it can be implemented in several ways: purely in software, or through a hardware gadget, such as a USB device. Also Android is certified.
The procedure has two parts:
- The registration: the client sends a public key to the server, which registers it.
- The authentication: the server asks the client to sign some data, and verifies that it can be decrypted with the public key it has registered.
Registration of credentials
Authentication
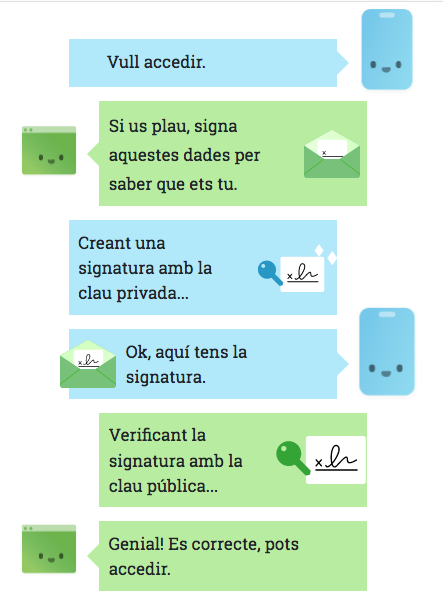
Oauth
OAuth is a web authorization protocol for granting websites access to some of your personal data or access rights to some system.
The goal is to obtain an access token to access a protected resource. There are four modes:
- Resource owner (resource owner): the user who authorizes an application to access their account.
- Client: The application that wants to access the user account.
- Resource server (resource server): contains the user accounts.
- Authorization server (authorization server): verifies identity and issues access tokens to the application.
These two servers are often referred to as the "Service API".
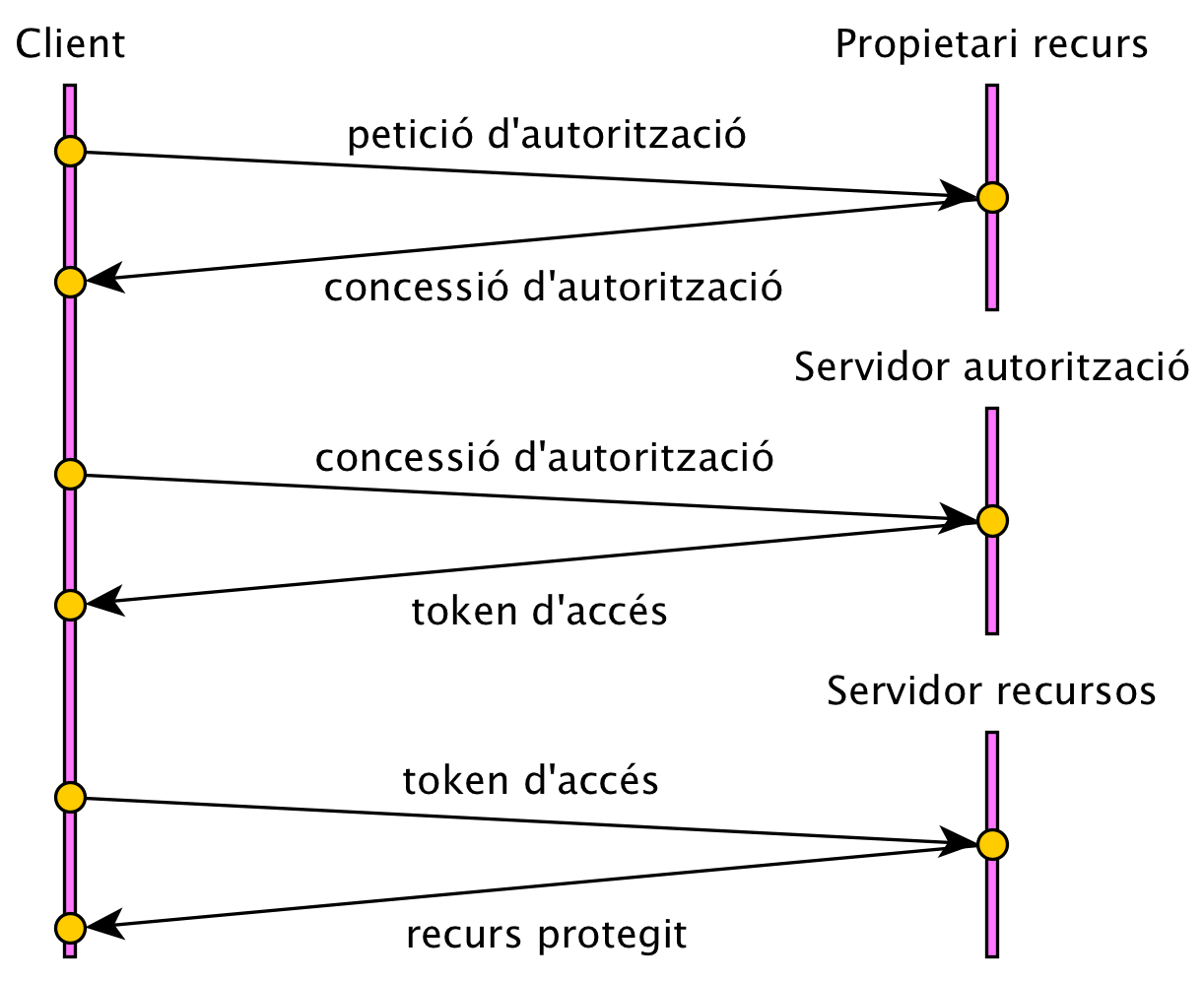
There are two concepts related to OAuth:
- Application registration: Before using OAuth, the application needs to register with the service by providing its name, web address and redirect URI, where the service will redirect after authorizing the 'application and where the application manages the access tokens. Registration generates a client ID and secret, used to authenticate the application to the API.
- The granting of authorization: 4 types are supported in OAuth 2:
- Authorization Code: The most common, used by server applications.
- Implicit: used by mobile or web applications (user device).
- Resource Owner Password Credentials: Used by trusted applications.
- Client Credentials: Used with Application API.
JSON Web Token (JWT)
JWT allows us to do authorization. It is an open standard based on JSON that allows the creation of access tokens to propagate identity and claims. The token is compact and can be sent in the web environment so that it can be stored on the client. The token is signed by the server (with a private key), so both the server and the client can verify that it is legitimate.
The standard statements are:
- iss: issuer
- sub: subject
- aud: audience
- exp: expiration time
- nbf: not before
- iat: issued at
- jti: JWT ID
Token-based authentication can be used to enable a stateless architecture, but it can also be used in stateful architectures. For example, a JWT can contain all necessary session data, encoded directly into the token, in which case it supports a stateless architecture. JWT can also be used to store a reference or ID for the session; in this case, the session data must be stored on the server side, making the architecture stateful.
A common operating scheme is the access token/refresh token:
- Access token: It does not go through the authentication server, it is only handled cryptographically. They don't last long (minutes).
- Refresh token: passes through the authentication server. They last longer, and can be revoked.